동시성의 정석 (2023.03.08)
저자: Matt Kline
요약
만약 본인이 시스템 쪽을 다루는 프로그래머라면, 뮤텍스mutex, 세마포어semaphore, 조건 변수conditional variable와 같은 단어들과 친숙할 것이다. 근데 친숙하다고 해서 이 도구들이 어떻게 작동하는지 안다는 것은 아닐 것이다. 게다가 만약 이 도구를 사용할 수 없는 상황이라면, 예를 들어 임베디드 환경과 같은 운영체제에서 개발을 할 때나 시간적 제약 때문에 블락block을 할 수 없을 때 동시성을 보장하는 코드를 어떻게 작성해야 하는지도 아리송할 것이다. 게다가 컴파일러와 하드웨어가 코드를 프로그래머가 작성하지 않은 버전으로, 작성된 순서나 로직을 따르지 않기도 하는데, 도대체 애초에 이 멀티스레드 프로그램들은 어떻게 동작을 하는 것일까? 동시성이라는 개념 자체가 매우 복잡하고 비직관적인 주제이지만, 기본 기초라도 우선 다뤄보도록 하자.
목차
- 배경
- 규칙 강제하기
- 원자성
- 임의 크기 “원자”형
- 읽기/수정하기/쓰기
- 교환
- 테스트와 설정
- 가져오기 및 …
- 비교 및 교체
- 구성 요소로서의 원자 연산
- 약순서 하드웨어에서의 순서 일관성
- LL/SC 명령어를 통한 원자 읽기/수정하기/쓰기 연산 구현
- 요상한 LL/SC 실패
- 언제나 순서 일관적인 연산이 필요한가?
- 메모리 순서
- 습득 및 방출
- 릴랙스드
- 습득-방출
- 소비
HC SVNT DRACONES
- 하드웨어 수렴
- 캐시 효과와 가짜 공유
- 동시성이 문제라면,
volatile이 답이 아니다 - 원자 융합
- 교훈
- 추가 자료
- 기여
1. 배경
현대적인 컴퓨터들은 동시에 여러 명령어의 흐름을 실행한다. 단일 코어의 경우 이 흐름 간에 서로 순서를 두고 짧은 시간만큼 CPU를 돌아가면서 사용한다. 다중 코어의 경우 몇몇 흐름은 병렬로 실행할 수 있다. 우리는 이걸 프로세스process, 스레드thread, 태스크task, 인터럽트 서비스 루틴interrupt service routine 등 여러 이름으로 부르는데, 어쨋든 대부분의 원칙은 동일하게 적용된다.
물론 컴퓨터 과학자들이 여러 훌륭한 추상적인 개념을 개발해냈지만, 이 명령어의 흐름(글의 가독성을 위해 앞으로 스레드라 칭하겠다.)은 궁극적으로는 상태의 일부를 서로 공유하는 방법으로 상호작용하게 된다. 이것이 가능하려면 스레드가 메모리를 읽고 쓰는 순서를 먼저 이해해야 한다. 간단한 예시를 들어보자. 스레드 A가 다른 스레드들과 한 정수를 공유한다고 해보자. 스레드 A가 이 정수를 수정한 다음 다른 스레드들에게 이 값이 변경됐음을 알리기 위해 플래그flag 하나를 셋팅해준다. 코드로 작성한다면 다음과 같은 형태를 띨 것이다:
int nValue = 0;
bool bIsValueReady = false;
void ThreadA()
{
// 정수의 값을 수정 (쓰기)
// 사용 가능 여부 플래그 셋팅
nValue = 42;
bIsValueReady = true;
}
void ThreadB()
{
// 값이 바뀔 때까지 대기했다가 값 읽어오기
while (!bIsValueReady)
{
// 대기
}
const int nMyValue = nValue;
// nMyValue로 무언가 작업을 하기...
}
여기서 중요한 전제는 다른 스레드 입장에선 스레드 A가 정수의 값을 먼저 바꾸고 나서 플래그를 셋팅하는 것을 확인한다는 것이다. (만약 다른 스레드가 nValue의 값이 42가 되기도 전에 bIsValueReady가 참이 되는 것을 “보게” 된다면 이 간단한 예제는 제대로 작동하지 않을 것이다.)
여러분은 당연히 언제나 이 순서가 보장이 될 것이라고 생각하겠지만, 현실은 보이는 것만으로는 알 수 없는 경우도 있다. 이 말을 처음 들은 분들을 위해 차근 차근 설명하자면, 우선 그 어떤 컴파일러든 일단 최적화를 해주는 컴파일러라면 타겟 하드웨어에서 더 빠르게 코드가 돌 수 있도록 코드를 재작성해주게 된다. 어쨋든 결과적으로 번역된 명령어들이 현재 스레드에서는 적어도 똑같이 작동만 한다면 파이프라인 지연pipeline stall[1]을 피하거나 지역성 개선[2]을 위해서 읽기 쓰기의 순서가 바뀔 수도 있는 것이다. 만약 서로 다른 두 변수가 동시에 사용되지만 않는다면 둘이 같은 메모리에 위치해있을 수도 있다. 계산 같은 경우도 분기가 오기 전에 대충 적당히 찍어 두고, 만약 컴파일러가 찍은 값이 잘못 되었다면 찍은 값은 무시한다.[3]

CC BY-SA 3.0, Link
[그림 1]: 불러오기, 해석하기, 실행하기, 메모리 접근하기, 라이트백write-back하기로 이루어진 전통적인 5단계 CPU 파이프라인. 현대에서 사용하는 설계는 이보다 더 복잡하고, 실행 도중에 명령어 순서가 자주 뒤바뀌기도 한다.
설사 컴파일러가 코드를 변경하지 않았다고 하더라도 어차피 하드웨어도 마찬가지로 비슷한 일을 하기 때문에 문제가 발생한다. 현대 CPU는 [그림 1]의 전통적인 파이프라인 방법보다 훨씬 더 복잡한 방법으로 명령어를 처리한다. 여기엔 수많은 데이터 경로가 존재하는데, 이 경로들은 각 명령어 종류 별로, 그리고 이 경로를 따라 명령어를 재정렬하고 타고 들어갈route 스케줄러 별로 존재한다.
또한 메모리의 작동 방법에 대해서도 순진하게 생각하고 있을 수도 있다. 다중 코어 프로세서의 경우 아래 [그림 2]에서처럼 각 코어가 순서를 지키면서 시스템의 메모리에 읽고 쓴다고 생각할 수도 있다.
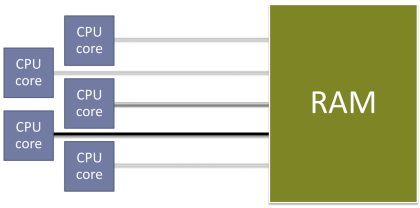
[그림 2]: 하나의 공유 메모리를 순서를 지키며 접근하는 이상적인 다중 코어 프로세서.
그러나 언제나 그렇듯 세상은 그리 쉽지 않다. 최근 수십년 간 프로세서의 속도는 기하급수적으로 증가해버려 RAM이 이 속도를 따라오지 못했다. 명령어를 실행하는데 걸리는 시간과 메모리로부터 데이터를 갖고 오는 시간 간의 간격이 역대급으로 커져버린 것이다. 이걸 해결하기 위해 하드웨어 설계자들은 갈수록 크기가 커지는 계층적인 캐시cache를 CPU 안에 직접 설치하여 문제를 나름 해결해주었다. 또한 일반적으로 각 코어마다 현재 쓰기 연산을 처리하는 동안 그 뒤에 있는 명령어를 실행할 수 있도록 쓰기 연산을 담당할 저장 버퍼store buffer를 갖고 있다. 이러한 메모리 체계에서 한 코어가 쓰기 연산을 하면 다른 코어가 서로 다른 캐시를 사용한다 하더라도 연산 결과가 적용되도록(역자: 다른 코어의 캐시에서도 똑같이 적용 되도록. 현재 서로 같은 메모리를 보고 있다는 가정이므로 쓰기 연산을 한 메모리 부분을 다른 코어에서도 캐시로 갖고 있을 수도 있으므로.) 일관성있게 만드는 것은 매우 어려운 일이다.
이러한 복잡한 상황은 결국 멀티스레드 프로그램에서는, 특히 다중 코어 CPU를 사용할 경우 일관성 있는 “지금”은 존재할 수가 없다. 스레드 간에 최소한 순서라는 느낌을 주려면 하드웨어, 컴파일러, 프로그래밍 언어, 어플리케이션 모두의 노력이 필요하다. 그래서 우리가 무엇을 할 수 있고, 어떤 도구가 필요한지를 한 번 다뤄보자.
2. 규칙 강제하기
12. 캐시 효과와 가짜 공유
- 대부분의 CPU 설계는 몇몇 명령어는 병렬로 실행시켜 처리율을 향상시킨다 ([그림 1] 참고). 만약 어떤 한 명령어가 바로 직전 명령어의 결과가 필요한 상태라면, CPU 입장에서는 결과를 받을 때까지 계속해서 진행을 중단, 즉 지연stall시킬 수 밖에 없다.
- RAM은 바이트 단위로 읽지 않고 캐시 줄cache line이라는 단위로 읽는다. 만약 같이 사용할 변수가 같은 캐시 줄에 있다면 한 번에 읽어올 수 있다는 뜻이다. 이렇게 되면 매우 속도가 빨라지지만 나중에 12장에서 보겠지만 코어 간 줄을 공유해야 할 땐 문제가 될 수도 있다.
- 프로파일링 기반 최적화를 할 경우 특히 일반적으로 발생한다.