Rendering Pipeline Study Notes (2022.06.03)
References
SIGGRAPH: Advances in Real-Time Rendering in Games
- 2008
- Starcraft II: Effects and Techniques. Dominic Filion, Blizzard. Rob McNaughton, Blizzard Entertainment.
- 2009
- Light Pre-Pass; Deferred Lighting: Latest Development. Wolfgang Engel.
- 2010
- CryENGINE 3: Reaching the Speed of Light. Anton Kaplanyan, Crytek.
- 2015
- GPU-Driven Rendering Pipelines. Ulrich Haar, Lead Programmer 3D, Ubisoft Montreal. Sebastian Aaltonen, Senior Lead Programmer, RedLynx a Ubisoft Studio
- 2016
- Deferred Lighting in Uncharted 4. Ramy El Garawany, Naughty Dog.
- 2018
- The Road toward Unified Rendering with Unity’s High Definition Render Pipeline. Evgenii Golubev, Unity.
- 2020
- Software-Based Variable Rate Shading in Call of Duty: Modern Warfare. Michal Drobot, Infinity Ward / Activision.
- 2021
- Geometry Rendering Pipeline Architecture. Michal Drobot, Infinity Ward / Activision.
- Rendering Engine Architecture at Activision. Michael Vance, Activision.
- Roblox (Rendering) Engine Architecture. Angelo Pesce, Roblox.
- Unity Rendering Architecture. Natalya Tatarchuk, Unity.
SIGGRAPH
- 2015
- Introduction to Real-Time Shading with Many Lights. Ola Olsson, Chalmers University of Technology.
- Practical Clustered Shading. Emil Persson, Avalanche Studios.
SIGGRAPH Asia
- 2014
- Introduction to Real-Time Shading with Many Lights. Ola Olsson, Chalmers University of Technology.
JCGT
- 2013
- The Visibility Buffer: A Cache-Friendly Approach to Deferred Shading. Christopher A. Burns, Intel Labs. Warren A. Hunt, Intel Labs.
- 2017
- Triangle Reordering for Efficient Rendering in Complex Scenes. Songfang Han, Hong Kong UST. Pedro Sander, Hong Kong UST.
HPG
- 2012
- Clustered Deferred and Forward Shading. Ola Olsson, Chalmers University of Technology. Markus Billeter, Chalmers University of Technology. Ulf Assarsson, , Chalmers University of Technology.
- 2015
- Deferred attribute interpolation for memory-efficient deferred shading. Christoph Schied, Karlsruhe Institute of Technology. Carsten Dachsbacher, Karlsruhe Institute of Technology.
GDC
- 2004
- Deferred Shading. Shawn Hargreaves, CLIMAX.
- 2007
- 2011
- Deferred Shading Optimizations. Nicolas Thibieroz.
- 2016
- Optimizing the Graphics Pipeline with Compute. Graham Wihlidal, Frostbite Engine / Electronic Arts.
- Rendering Rainbox Six Siege. Jalal El Mansouri, Ubisoft Montreal.
- 2020
- Lima Oscar Delta!: Scaling Content in ‘Call of Duty: Modern Warfare’. Rulon Raymond, Infinity Ward / Activision.
Digital Dragons
- 2017
- Rendering of Call of Duty: Infinite Warfare. Michal Drobot, Infinity Ward / Activision.
Books
- ShaderX2
- Deferred Shading with Multiple Render Targets. Nicolas Thibieroz.
- ShaderX5
- Overcoming Deferred Shading Drawbacks. Frank Puig Placeres.
- ShaderX7
- Designing a Renderer for Multiple Lights: The Light Pre-Pass Renderer. Wolfgang Engel, Rockstar Games.
- GPU Gems 1
- Graphics Pipeline Performance
- GPU Gems 2
- Deferred Shading in S.T.A.L.K.E.R.. Oles Shishkovtsov, GSC Game World.
- GPU Gems 3
- Deferred Shading in Tabula Rasa. Rusty Koonce, NCSoft Corporation.
- GPU Pro 4
- Decoupled Deferred Shading on the GPU
- Tile Forward Shading
- Forward+: A Step Toward Film-Style Shading in Real-Time. Takahiro Harada, AMD. Jay McKee, AMD. Jason C. Yang, AMD.
- GPU Zen
- Deferred+. Hawar Doghramachi, Eidos-Montreal. Jean-Normand Bucci, Eidos-Montreal.
- Optimizing the Graphics Pipeline with Compute
- Ray Tracing Gems
- Hybrid Rendering for Real-Time Ray Tracing
- Deferred Hybrid Path Tracing
Blog
- 2003
- Photo-Realistic Deferred Lighting. Dean Calver.
- 2016
- Triangle Visibility Buffer. Wolfgang Engel.
- 2018
- A Primer on Efficient Rendering Algorithms & Clustered Shading. Ángel Ortiz, Rockstart North.
- Dissecting the Rendedring of The Surge. Philip Hammer, id Software.
- 2019
- Resident Evil 2 Frame Breakdown. Anton Schreiner.
- Anatomy of a frame in AnKi. Panagiotis Christopoulos Charitos, ARM.
- 2020
- Samurai Shading in Ghost of Tsushima. Jasmin Patry, Sucker Punch Productions.
- Clustered shading evolution in Granite. Maister.
- Unmasking the Arkham Knight. m0radin.
- 2021
- The Rendering of Jurassic World: Evolution. Code Corsair.
- Graphics Pipelines for Young Bloods. Jeremy Ong, Amazon Web Services.
- The Rendering of Mafia: Definitive Edition. Code Corsair.
Study Notes
Forward Rendering
Simple pseudo-code:Ortiz18
// Shaders
Shader simpleShader
// Buffers:
Buffer display
for mesh in scene
for light in scene
display += simpleShader(mesh, light)
- AdvantagesOlsson14
- Single pass
- Low storage overhead
- Single frame buffer
- Simple if only few lights (e.g., the sun)
- MSAA works
- Varying shading models is easy
- Transparency works
- Issues:
- Computing which lights affect each body consumes CPU time, worst case O(n × m) operationKoonce07
- Shader often require more than one render pass to perform lighting, worst cast O(n) render passes for n lightsKoonce07Ortiz18
- Adding new lighting models or light types requires changing all effect source filesKoonce07
- Shaders quickly encounter the instruction count limit of Shader Model 2.0Koonce07
- OverdrawingOlsson14Ortiz18
- Multi PassOlsson14
- Light managementOlsson14
- Expensive for many lights
- Batching coupled with lightingOlsson14
- Shader managementOlsson14
- Permutations of #lights/type
Single PassValient07
- For each object
- Find all lights affecting object
- Render all lighting and material in a single shader
- Shader combinations explosion
- Shader for each material vs light setup combination
- All shadow maps have to be in memory
- Waster shader cycles
- Invisible surfaces / overdraw
- Triangles outside light influence
Multi-PassValient07
- For each light
- For each object
- Add lighting from single light to frame buffer
- Shader for each material and light type
- Wasted shader cycles
- Invisible surfaces / overdraw
- Triangles outside light influence
- Lots of repeated work
- Full vertex shaders, texture filtering
Examples
Example 1: Jurassic World EvolutionCodeCorsair0321
- Tiled Forward Lighting
- 8 x 8 pixel tiles
- Depth Prepass
- Thin GBuffer
- Normal + roughness
- Motion Vectors
Deferred Shading
- For each objectValient07
- Render surface properties into the G-Buffer
- For each light and lit pixelValient07
- Use G-Buffer to compute lighting
- Add result to frame buffer
Simple Z pre-pass pseudo-code:Ortiz18
// Buffers:
Buffer display
Buffer depthBuffer
// Shaders:
Shader simpleShader
Shader writeDepth
// Visibility
for mesh in scene
if mesh.depth < depthBuffer.depth
depthBuffer = writeDepth(mesh)
// Shading and lighting
for mesh in scene
if mesh.depth == depthBuffer.depth
for light in scene
display += simpleShader(mesh, light)
Simple multi-pass deferred rendering pseudo-code:Ortiz18
// Buffers:
Buffer display
Buffer GBuffer
// Shaders:
Shader simpleShader
Shader writeShadingAttributes
// Visibility & materials
for mesh in scene
if mesh.depth < GBuffer.depth
GBuffer = writeShadingAttributes(mesh)
// Shading & lighting - multi-pass
for light in scene
display += simpleShader(GBuffer, light)
Simple single-pass deferred rendering pseudo-code:Ortiz18
// Buffers:
Buffer display
Buffer GBuffer
// Shaders:
Shader manyLightShader
Shader writeShadingAttributes
// Visibility & materials
for mesh in scene
if mesh.depth < GBuffer.depth
GBuffer = writeShadingAttributes(mesh)
// Shading & lighting - multi-pass
display = manyLightShader(GBuffer, scene.lights)
- Advantages
- Uses single geometry passThibieroz03Olsson14
- Performs all shading calculations per-pixelThibieroz03
- Reduces pixel overdrawThibieroz03
- Lights major cost is based on the screen area covered (shading / lighting only applied to visible fragments)Calver03Shishkovtsov05Thibieroz11
- Lights can be occluded like other objects, this allows fast hardware Z-RejectCalver03
- Shadow mapping is fairly cheapCalver03Olsson14
- Adding more layers of effects generally results in a linear, fixed cost per frame for additional full-screen post-processing passes regardless of the number of models on screenValient07FilionMcNaughton08
- Scene geometry decoupled from lightingKoonce07Kaplanyan10Thibieroz11
- Reduction in render statesKoonce07Thibieroz11
- G-Buffer already produces data required for post-processingThibieroz11
- Excellent batchingHargreaves04
- Render each triangle exactly onceHargreaves04Olsson14
- Shade each visible pixel exactly onceHargreaves04
- Easy to add new types of lighting shader, simple shadersHargreaves04Valient07Koonce07
- Gives artistic freedomValient07
- MSAA did not prove to be an issue
- Complex geometry with no resubmit
- Highly dynamic lighting in environments
- Extensive post-process
- Perfect depth complexity for lightingShishkovtsov05
- Simplified scene managementShishkovtsov05
- Ability to cut down on large numbers of batchesShishkovtsov05
- Reduced CPU usageShishkovtsov05
- Enables many lightsOlsson14
- Trivial light managementOlsson14
- Simple (light) shader managementOlsson14
- Good decomposition of lightingKaplanyan10
- No lighting-geometry interdependency
- Considerations
- Memory footprint (Large frame-buffer size)Thibieroz03Calver03FilionMcNaughton08Kaplanyan10Thibieroz11Olsson14
- Bandwidth requirements (Potentially high fill-rate)Thibieroz03Calver03Hargreaves04Placeres06FilionMcNaughton08Kaplanyan10Olsson14
- Multiple light equations difficultCalver03
- Transparency is very hard. Forward rendering required for translucent objectsCalver03Hargreaves04Placeres06Valient07Kaplanyan10Thibieroz11Olsson14
- Comparatively expensive to have multiple light models
- Antialiasing. Costly and complex MSAAHargreaves04Placeres06Kaplanyan10Thibieroz11Olsson14
- Significant engine reworkThibieroz11
- Forces a single lighting model across the entire scene (everything has to be 100% per-pixel)Hargreaves04Olsson14
- Accumulates light in frame bufferOlsson14
- High precision needed
- Limitied materials variationsKaplanyan10
Builds an attribute buffer, also known as the G-Buffer.Thibieroz03Calver03
For each object:
Render to MRT
For each light:
Apply light as a 2D postprocess
Geometry Phase
- The only phase that actually uses an objects mesh dataCalver03
- Output is G-BufferCalver03
- Fill the G-Buffer with all geometry (static, skinned, etc.)Valient07
- Initialize light accumulation buffer with pre-baked lightValient07
- Ambient, incandescence, constant specular
- Lightmaps on static geometry
- YUV color space, S3TC5 with Y in Alpha
- Sun occlusion in B channel
- Dynamic range [0…2]
- Image based lighting on dynamic geometry
- Some portions of the light equation that stay constant can be computed here and stored in the G-Buffer if necessary (ex. Fresnel)Calver03
- Precision is important when creating G-BuffersFilionMcNaughton08
- Don’t bother with any lighting while drawing scene geometryHargreaves04
- Render to a “fat” framebuffer format, using MRT to store data (position, normal, etc.)Hargreaves04
G-Buffer Building PassThibieroz11
How to reduce export cost (PS to MRT)?
- Render objects in front-to-back order
- Use fewer RTs
- Each RT adds to export cost
- Avoid slow formats
- NVIDIA
- RT export cost proportional to bit depth except 32bpp same speed as 32bpp sRGB formats are slower
- Total export cost = Cost(RT0) + Cost(RT1) + …
- AMD
- R32G32B32A32, R32G32, R32, R32G32B32A32f, R32G32f, R16G16B16A16 (+ R32F, R16G16, R16 on older GPUs)
- Total export cost = (Num RTs) * (Slowest RT)
- NVIDIA
- Depth Buffer as Texture Input
- No need to store depth into a color RT
- Data Packing
- Trade render target storage for a few extra ALU instructions
- ALU cost is typically negligible compared to the performance saving of writing and fetching to/from fewer textures
What to Store?
- PositionCalver03
- World Space?
- Screen Space?
- Costs a few extra instructions to undo, but the advantages in bandwidth and visual fidelity make it worthwhile
- Distance
- Instead of storing positions, store the distance of the position in view spacePlaceres06
G_Buffer.z = length(Input.PosInViewSpace)
- Each 2D screen pixel corresponds to a ray from the eyepoint into the 3D worldHargreaves04
- Retrieval:Placeres06
- VS
out.vEyeToScreen = float3(Input.ScreenPos.x * ViewAspect, Input.ScreenPos.y, invTanHalfFOV);
- PS
float3 PixelPos = normalize(Input.vEyeToScreen) * G_Buffer.z;
- VS
- Instead of storing positions, store the distance of the position in view spacePlaceres06
- Normal
- Because normal vectors are unit length vectors, z = ± √ (1 - x2 - y2)Placeres06
- If all the lighting is performed in view space, then the front-faced polygons are always going to have negative / positive Z components depending on the frame of reference used
- Single byte is commonly used for a normal component when dealing with normal maps or other precomputed texturesPlaceres06
- Store normals in A2R10G10B10Hargreaves04
- Normals at 24bpp are too quantized, lighting is of a low qualityKaplanyan10
- 24bpp = 256 x 256 x 256 cells = 16,777,216 values
- However, we are storing the normalized normals:
- 289,880 cells out of 16,777,216 cells ~ 1.73%
- Use a normal cube map
- Because normal vectors are unit length vectors, z = ± √ (1 - x2 - y2)Placeres06
- Color
- Material Atrributes
- Specular power, glow factor, occlusion term, etc.Placeres06
- Such values normally differs by material, and often could be constrained to specific valuesPlaceres06
- If the specular power term can be constrained into [1, 4, 10, 20], then only two bits can be used to store the specular term
- If a scene contains few materials, then a G-Buffer can hold a material id value to be used as an index to the material look-up tablePlaceres06
- Could be palettized, then looked up in shader constants or a textureHargreaves04
Examples
Example 1Calver03
| GBuffer | |||
| Pos.X | Pos.Y | Pos.Z | ID |
| Norm.X | Norm.Y | Norm.Z | MaterialIndex |
| Albedo.R | Albedo.G | Albedo.B | DiffuseTerm |
| SpecularEmissive.R | SpecularEmissive.G | SpecularEmissive.B | SpecularTerm |
| Material Lookup Texture |
|---|
| Kspecblend |
| KAmb |
| KEmm |
| … |
Example 2 : StarCraft IIFilionMcNaughton08
- Only opaque objects with some notable exceptions
- Only local lights
- Point and spot lights with a defined extent in space
- Global directional lights are forward rendered normally
- Color components not affected by local lighting (emissive, environment maps, forward-lit color components)
- Depth
- Lighting, fog volumes, dynamic AO, smart displacement, DoF, projections, edge detection, thickness measurement
- Per-pixel normal
- Dynamic AO
- Ambient occlusion term, if using static AO. Baked AO textures are ignored if screen-space AO is enabled
- Unlit diffuse material color
- Lighting
- Unlit specular material color
- Lighting
- Due to heavy use of HDR, all these buffers will normally be four-channel 16-bit floating point formats
| MRTs | GBuffer | |||
| MRT 0 | UnlitAndEmissive.R | UnlitAndEmissive.G | UnlitAndEmissive.B | Unused |
| MRT 1 | Normal.X | Normal.Y | Normal.Z | Depth |
| MRT 2 | Albedo.R | Albedo.G | Albedo.B | AO |
| MRT 3 (optional) | Specular.R | Specular.G | Specular.B | Unused |
Example 3 : GDC 2004Hargreaves04
- Position : A32B32G32R32F
- Normal : A16B16G16R16F
- Diffuse Color : A8R8G8B8
- Material Parameters : A8R8G8B8
- 256 bits per pixel
Optimized Version:
- 128 bits per pixel
- Depth : R32F
- Can be optimized by using Depth buffer directly
- Normal + scattering : A2R10G10B10
- 2 bit subsurface scattering control
- Diffuse color + emissive : A8R8G8B8
- Other material parameters : A8R8G8B8
- Specular intensity, specular power, occlusion factor, shadow etc.
Example 4 : Killzone 2Valient07
- Depth
- View-space normal
- Specular intensity
- Specular roughness / Power
- Screen-space 2D motion vector
- Albedo (texture color)
After deferred composition, post-processing(DoF, bloom, motion blur, colorize, ILR) is applied
| MRTs | R8 | G8 | B8 | A8 |
| DS | Depth 24bpp | Depth 24bpp | Depth 24bpp | Stencil |
| RT 0 | Lighting Accumulation R | Lighting Accumulation G | Lighting Accumulation B | Intensity |
| RT 1 | Normal.X (FP16) | Normal.X (FP16) | Normal.Y (FP16) | Normal.Y (FP16) |
| RT 2 | Motion Vectors X | Motion Vectors Y | Spec-Power | Spec-Intensity |
| RT 3 | Diffuse Albedo R | Diffuse Albedo G | Diffuse Albedo B | Sun-Occlusion |
- MRT - 4xRGBA8 + 24D8S (approx 36 MB)
- 720p with Quincux MSAA
- Position computed from depth buffer and pixel coordinates
- Light accumulation - output buffer
- Light is rendered as convex geometry
- Point light - sphere
- Spot light - cone
- Sun - full-screen quad
- For each light
- Find and mark visible lit pixels
- Mark pixels in front of the far light boundary
- Render back-faces of light volume
- Depth test GREATER-EQUAL
- Write to stencil on depth pass
- Skipped for very small distant lights
- Find amount of lit pixels inside the volume
- Start pixel query
- Render front faces of light volume
- Depth test LESS-EQUAL
- Don’t write anything - only EQUAL stencil test
- Mark pixels in front of the far light boundary
- If light contributes to screen
- Render shadow map
- Shade lit pixels and add to framebuffer
- Render front-faces of light volume
- Depth test - LESS-EQUAL
- Stencil test - EQUAL
- Runs only on marked pixels inside light
- Compute light equation
- Read and unpack G-Buffer atrributes
- Calculate light vector, color, distance attenuation
- Perform shadow map filtering
- Add Phong lighting to frame buffer
- Render front-faces of light volume
- Find and mark visible lit pixels
- Intensity - luminance of lighting accumulation
- Scaled to range [0…2]
- Normal.z = sqrt(1.0f - Normal.x2 - Normal.y2)
- Motion vectors - screen space
- Specular power - stored as log2(original) / 10.5
- High range and still high precision for low shininess
- Sun occlusion - pre-rendered static sun shadows
- Mixed with real-time sun shadow for higher quality
Analysis:
- Pros:
- Highly packed data structure
- Many extra attributes
- Allows MSAA with hardware support
- Cons:
- Limited output precision and dynamic range
- Lighting accumulation in gamma space
- Can use different color space (LogLuv)
- Attribute packing and unpacking overhead
- Limited output precision and dynamic range
Light Optimization:
- Determine light size on the screen
- Approximation - angular size of light volume
- If light is “very small”
- Don’t do any stencil marking
- Switch to non-shadow casting type
- Shadows fade-out range
- Artist defined light sizes at which:
- Shadows start to fade out
- Switch to non-shadow casting light
- Artist defined light sizes at which:
Example 5 : Mafia: Definitive EditionCodeCorsair0821
- Depth Prepass
- GBuffer Pass
| MRTs | R | G | B | A |
| RT 0 | Normal.X R16F | Normal.Y G16F | Normal.Z B16F | Roughness A16F |
| RT 1 | Albedo.R R8 | Albedo.G G8 | Albedo.B B8 | Metalness A8 |
| RT 2 | MotionVectors.X R16U | MotionVectors.Y G16U | MotionVector.Z B16U | Encoded Vertex Normal A16U |
| RT 3 | Specular Intensity R8 | 0.5 G8 | Curvature or Thickness (for SSS) B8 | SSS Profile A8 |
| RT 4 | Emissive.R R11F | Emissive.g G11F | Emissive.b B11F |
Example 6: Resident Evil 2Schreiner19
- Depth prepass
- G-Buffer pass Geometry + Decals
| MRTs | R | G | B | A |
| RT 0 | Emissive.R R11 | Emissive.G G11 | Emissive.B B10 | |
| RT 1 | Albedo.R R8 | Albedo.G G8 | Albedo.B B8 | Metalness A8 |
| RT 2 | Normal.R R10 | Normal.G G10 | Roughness B10 | Miscellanous A2 |
| RT 3 | Baked AO R16 | Velocity.Y G16 | Velocity.Z B16 | SSS A16 |
Example 7: Batman: Arkham KnightsMoradin20
| MRTs | R | G | B | A |
| RT 0 | Emissive.R R11 | Emissive.G G11 | Emissive.B B10 | |
| RT 1 | Normal.X R10 | Normal.Y G10 | Normal.Z B10 | A2 |
| RT 2 | Albedo.R R8 | Albedo.G G8 | Albedo.B B8 | Material Masking A8 | RT 3 | Material Properties R8 | Material Properties G8 | Material Properties B8 | Material Properties A8 | </tr>
Lighting Phase
-
Apply lighting as a 2D postprocess using MRT buffers as inputHargreaves04
- Full screen lightsCalver03
- Use full screen quad
- Ambient lighting, hemispherical lighting, sun directional lighting etc.
- Shaped LightsCalver03
- Using attenuations, we can cull the lights that no longer makes any contribution per-pixel
- Based on the attenuation model, calculate which pixels are beyond the ranges and try not to run the pixel shaders
- We can project the light volumes where the lighting contribution isn’t zero
- Each pixel most be hit once and once only
- Projected geometry must not be clipped by the near/far planes
- Remove the far plane by setting it into infinity
Full screen lighting is actually slower than forward rendering.
- Stenciling allows us to discard pixels that are covered by the light shapes but whose depth is too far behind the light to be affected by itThibieroz11
- Early-Z will reduce cost of hidden lightsThibieroz11
- Early stencil reduces cost of objects behind light that are not lit by itThibieroz11
- Light shapes must be rendered again with color writes off before its normal lighting pass
- Stencil operation is slightly different depending on whether the viewing camera sits inside the light shape (this has to be tested on the CPU)
- If the camera is outside the light shape, only pass front facing parts
- Else, color any of the light shape’s back facing pixels that failed the z-test
- High-Level ManagerPlaceres06
- Only sends the sources that influence the final image to the pipeline and executes the shaders only on the pixels that are influenced by the effect or light
- Receives the list of all sources that should modulate the resulting render and all the information about them
- One such piece of information: Bounding object that contains information on how strong the source effect should be applied to the rendering equation
1. Social Stage
- Execute visibility and occlusion algorithms to discard lights whose influence is not appreciable
- Using the source-bounding object, the manager finds which lights and effects are not occluded by the scene geometry and are inside the view frustum 2. Project visible sources bouding objects into screen space 3. Combine similar sources that are too close in screen space or influence almost the same screen area 4. Discard sources with a tiny contribution because of their projected bounding object being too small or too far 5. Check that more than a predefined number of sources do not affect each screen region. Choose the biggest, strongest, and closer sources 2. Individual Phase
- Lights and special effects in general can be classified in two main groups: global sources, local sources
- Global Sources
- Sun, DoF, fog, etc.
- For each global sources:
- Enable the appropriate shaders
- Render a quad covering the screen
- Local Sources
- Only affect regions of the scene
- Volumetric fog, heat haze, etc.
- Pixels inside the source bounding-object have to be processed 1. Select the appropriate level of detail
- Farther and smaller sources don’t have to be computed with the same quality than closer sources 2. If dynamic branching is not supported, render a mask in the stencil buffer
- If dynamic branching is supported, if the pixel position is not found to be in the influence area of the bounding object, then the pixel is discarded 3. Enable and configure the source shaders 4. Compute the minimum and maximum screen cord values of the projected bounding object 5. Enable the scissor test
- Using the rectangle that surrounds the screen projection of the source bounding object
- Quickly rejects pixels at the fragment level 6. Enable the clipping planes
- Further restrain the pixels that get into the fragment stage from the transform level 7. Render a screen quad or the bounding object
- One such piece of information: Bounding object that contains information on how strong the source effect should be applied to the rendering equation
1. Social Stage
Shading PassesThibieroz11
- Add light contributions to accumulation buffer
- Light Volumes vs Screen-aligned quads
- Cull lights as needed before sending them to the GPU
- Don’t render lights on skybox area
- S.T.A.L.K.E.R. uses hierarchical occlusion-culling system that utilized both the CPU and the GPUShishkovtsov05
- Coarsest test was sector-portal culling followed by CPU-based occlusion culling (similar to the hierarchical z-buffer)
- Most lighting in Ghost of Tsushima is deferred:Patry20
- Lambertian diffuse
- Optional translucency
- Optional simplified asperity scattering (fuzziness)
- Isotropic GGX specular
- Optional colored specular via “metallic” channel
- Lambertian diffuse
- Other materials are forward lit, e.g. when using:Patry20
- Anisotropic GGX specular
- Full anisotropic asperity scattering BRDF
- Subsurface scattering
Tiled Shading
The Bandwith problem:
- New type of overdraw
- Light overdraw
- N lights cover a certain pixel
- N reads from the same G-Buffer location
- Deferred shading
for each light
for each covered pixel
read G-Buffer
compute shading
read + write frame buffer // requires repeated reading and writing of the G-Buffers and frame buffer
for each pixel
read G-Buffer
for each affecting light
compute shading
write frame buffer // single write
- This scheme requires sequential access to lights for each pixel
- Global list
- inefficient
- List per pixel
- Lots of data
- Slow construction
- Share list in screen space tiles
- e.g. 32 x 32 pixels
- Simple construction
- little storage
- 1 list per 1024 pixels
- coherent access
- Global list
- For each light,
- Find screen space AABB to the light
- Add index of the light to affected tiles
- Perform min/max depth to cull away lights occupying empty space
- Global Light List
- Tile Light Index Lists
- Light Grid
- 2D grid
- Each cell stores an offset and count that represent a range in a global buffer
ex)
| Global Light List | ||||||||
|---|---|---|---|---|---|---|---|---|
| L0 | L1 | L2 | L3 | L4 | L5 | L6 | L7 | … |
| Tile Light Index Lists | ||||||||
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 6 | 3 | 0 | 6 | 4 | 4 | … |
| Tile Light Index Lists | ||||
|---|---|---|---|---|
| 0 | 1 | 4 | 7 | … |
| 1 | 3 | 3 | 1 | … |
| 66 | 67 | 69 | … | … |
| 1 | 2 | 2 | … | … |
- Light grid provides:
- Access to light list for each pixel
- List shared within tile
- Low memory usage
- Good access coherency
- Not pixel exact
- Light grid building
- Is pretty quick
- CPU for hundres of lights
- Render Scene to G-Buffers
- Store geometry attributes per pixel
- G-Buffers
- Store geometry attributes per pixel
- Build Light Grid
- Full Screen Quad (or CUDA, or Compute Shaders, or SPUs)
- For each pixel
- Fetch G-Buffer Data
- Find Tile
- Loop over lights and accumulate shading
- Write shading
- For each pixel
- Depth Range Optimization
- Min/Max depth per tile
- For each light
- Test depth bounds
- If light volume does not intersects with the depth bounds, then reject the light
- However…
- Tiles: 2D
- Geometry Samples: 3D
- Fragments / Pixels
- Light density: 3D
- View dependent
- Unpredictable shading times
Simple single-pass deferred rendering using tiled shading pseudo-code:Ortiz18
// Buffers:
Buffer display
Buffer GBuffer
Buffer tileArray
// Shaders:
Shader manyLightShader
Shader writeShadingAttributes
CompShader lightInTile
// Visibility & materials
for mesh in scene
if mesh.depth < GBuffer.depth
GBuffer = writeShadingAttributes(mesh)
// Light culling
for tile in tileArray
for light in scene
if lightInTile(tile, light)
tile += light
// Shading & lighting - multi-pass
display = manyLightShader(GBuffer, tileArray)
Based on the light attenuation, we can calculate the influence of a light to create a concrete volume of influence which is represented with different shapes for each type of light source.Ortiz18
Based on these shapes, perform a collision detection between the light volumes and tiles. Tile forward shading is sometimes also referred to as Forward+.Ortiz18
However, tiles has no information regarding the depth discontinuity of the lights.Ortiz18
Clustered Shading
If tiled shading is a 2D approach, clustered shading is a 3D approach.
Simple single-pass deferred rendering using clustered shading pseudo-code:
Buffer display
Buffer GBuffer
Buffer clusterArray
// Shaders:
Shader manyLightShader
Shader writeShadingAttributes
CompShader lightInCluster
// Visibility & materials
for mesh in scene
if mesh.depth < GBuffer.depth
GBuffer = writeShadingAttributes(mesh)
// Light culling
for cluster in clusterArray
for light in scene
if lightInCluster(cluster, light)
cluster += light
// Shading & lighting - multi-pass
display = manyLightShader(GBuffer, clusterArray)
- Adding the 3rd dimension
- Tile also in depth direction = cluster
- Bounded volume around samples
- Shading cost ~ Light density
- New Challenges
- Many more (potential) clusters
- Must find those actually used
- Adding lights no longer screen space
- Many more (potential) clusters
Algorithm:
- Rasterize G-Buffers
- Forward: pre-z pass
- Cluster assignment
- Cluster key:
- ck = (i, j, k) integer tuple
- i, j = 2D tile id
- Divide the fragment coordinate by the tile size
- k = ≈log(view space z)
- (quantized normal)
- Cluster key:
- Find unique clusters
- Full screen pass
- Flag used clusters
- Read depth
- Compute ck
- Set cell in grid to one
- Forward:
- Geometry pass with side effect
- Compact Non-Zero
- Yields list of non-empty clusters
- Parallel prefix sum
- chag::pp (CUDA)
- thrust (CUDA)
- Compute Shader API?
- Assign lights to clusters
- Many clusters
- Many lights
- Hierarchical approach
- Hierarchy over lights
- 32-way tree (matches SIMD of GPU)
- Dynamically rebuilt on GPU
- Each cluster traverses light tree
- BV tests
- Hierarchy over lights
- Shade view samples
- Deferred: Full screen pass
- Forward: Geometry pass
Light Volume Rendering
- Render light volumes corresponding to light’s range
- Fullscreen tri/quad (ambient or directional light)
- Sphere (point light)
- Cone / pyramid (spot light)
- Custom shapes (level editor)
- Tight fit between light coverage and processed area
- 2D projection of volume define shaded area
- Additively blend each light contribution to the accumulation buffer
- Use early depth / stencil culling optimizations
- Muse be geometry-optimized
- Index re-use(post VS cache), sequential vertex reads (pre VS cache)
- Common oversight for algorithmically generated meshes (spheres, cones, etc.)
- Especially important when depth/stencil-only rendering is used
- Use artist-defined clipping geometry: clip volumes
- Mast the stencil in addition to light volume masking
Screen-Aligned QuadsThibieroz11
- Rendering a camera-facing quad for each light
- Simpler geometry but coarser rendering
- Not as simple as it seems
- Spheres (point lights) project to ellipses in post-perspective space!
- Can cause problems when close to camera
- Additively render each quad onto accumulation buffer
- Process light equation as normal
- Set quad Z coordinates to Min Z of light
- Eary Z will reject lights behind geometry with Z Mode = LESSEQUAL
- Watch out for clipping issues
- Need to clamp quad Z to near clip plane Z if: Light Min Z < Near Clip Plane Z < Light Max Z
- Saves on geometry cost but not as accurate as volumes
Global Lights
- Sunlight, fog, etc.Hargreaves04
- Draw them as a fullscreen quadHargreaves04
- Based on the G-Buffer, calculate the lighting in the pixel shader, then output the results to an intermediate lighting bufferHargreaves04
Sun Rendering
- Full screen quadValient07
- Stencil mark potentially lit pixelsValient07
- Use only sun occlusion from G-Buffer
- Run final shader on marked pixelsValient07
- Approx. 50% of pixels skipped thanks to 1st pass
- Also skybox / background
- Simple directional light model
- Shadow = min(RealTimeShadow, Occlusion)
- Approx. 50% of pixels skipped thanks to 1st pass
Optimization:Shishkovtsov05
- Single 2048 x 2048-pixel shadow map for most of the sun lighting, using a perspective shadow map-style projection transform to maximize area near the viewer
- Skybox doesn’t need to be shaded (30 ~ 40% pixels)
- Approximately 50% percent of pixels face away from the sun
- Pixels that have an ambient occlusion term of zero cannot be reached by sun rays
Pass 0:
Render full-screen quad only where 0x03==stencil count (where attributes are stored)
If ((N dot L) * ambient_occlusion_term > 0)
discard fragment
Else
color = 0, stencil = 0x01
Pass 1:
Render full-screen quad only where 0x03==stencil count
Perform light accumulation / shading
Local Lights
- Only render the affected pixelsHargreaves04
- Project the light volume into screen-spaceHargreaves04
- At author time, build a simple mesh that bounds the area affected by the lightHargreaves04
- At run time, draw this in 3D space, running your lighting shader over each pixel that it coversHargreaves04
Convex Light Hulls
- Based on the position of the camera, light bounding mesh, light process has to be process differently
- It is important that each pixel only gets lit onceHargreaves04
- If the camera is inside the volume, draw backfacesHargreaves04
- If the light volume intersects the far clip plane, draw frontfacesHargreaves04
- If the light volume intersects both near and far clip planes, your light is too big!Hargreaves04
- Else, as long as the mesh is convex, backface culling can take care of thisHargreaves04
Stencil Light VolumesHargreaves04
- Finding the intersection between scene geometry and an extruded shadow volume
- Using stencil required changing renderstate for each light, which prevents batching up multiple lights into a single draw call
Light Volume Z TestsHargreaves04
- Drawing light volume backfaces:
D3DCMP_GREATERto reject “floating in the air” portions of the light
- Drawing front faces:
D3DCMP_LESSto reject “buried underground” light regions
Alpha Blending
- BIG PROBLEM!Hargreaves04
- Simply draw them after the deferred shadingHargreaves04
- Use forward rendering passValient07
- Single pass solution
- Shader has four uberlights
- No shadows
- Per-vertex lighting version for particles
- Lower resolution rendering available
- Fill-rate intensive effects
- Half and quarter screen size rendering
- Half resolution rendering using MSAA HW
- Single pass solution
HDR
- Render your scene to multiple 32 bit buffers, then use a 64 bit accumulation buffer during the light phaseHargreaves04
Antialiasing
struct v2p
{
float4 tc0: TEXCOORD0; // Center
float4 tc1: TEXCOORD1; // Left Top
float4 tc2: TEXCOORD2; // Right Bottom
float4 tc3: TEXCOORD3; // Right Top
float4 tc4: TEXCOORD4; // Left Bottom
float4 tc5: TEXCOORD5; // Left / Right
float4 tc6: TEXCOORD6; // Top / Bottom
};
/////////////////////////////////////////////////////////////////////
uniform sampler2D s_distort;
uniform half4 e_barrier; // x=norm(~.8f), y=depth(~.5f)
uniform half4 e_weights; // x=norm, y=depth
uniform half4 e_kernel; // x=norm, y=depth
/////////////////////////////////////////////////////////////////////
half4 main(v2p I) : COLOR
{
// Normal discontinuity filter
half3 nc = tex2D(s_normal, I.tc0);
half4 nd;
nd.x = dot(nc, (half3)tex2D(s_normal, I.tc1));
nd.y = dot(nc, (half3)tex2D(s_normal, I.tc2));
nd.z = dot(nc, (half3)tex2D(s_normal, I.tc3));
nd.w = dot(nc, (half3)tex2D(s_normal, I.tc4));
nd -= e_barrier.x;
nd = step(0, nd);
half ne = saturate(dot(nd, e_weights.x));
// Opposite coords
float4 tc5r = I.tc5.wzyx;
float4 tc6r = I.tc6.wzyx;
// Depth filter : compute gradiental difference:
// (c-sample1)+(c-sample1_opposite)
half4 dc = tex2D(s_position, I.tc0);
half4 dd;
dd.x = (half)tex2D(s_position, I.tc1).z + (half)tex2D(s_position, I.tc2).z;
dd.y = (half)tex2D(s_position, I.tc3).z + (half)tex2D(s_position, I.tc4).z;
dd.z = (half)tex2D(s_position, I.tc5).z + (half)tex2D(s_position, tc5r).z;
dd.w = (half)tex2D(s_position, I.tc6).z + (half)tex2D(s_position, tc6r).z;
dd = abs(2 * dc.z - dd)- e_barrier.y;
dd = step(dd, 0);
half de = saturate(dot(dd, e_weights.y));
// Weight
half w = (1 - de * ne) * e_kernel.x;
// 0 - no aa, 1=full aa
// Smoothed color
// (a-c)*w + c = a*w + c(1-w)
float2 offset = I.tc0 * (1-w);
half4 s0 = tex2D(s_image, offset + I.tc1 * w);
half4 s1 = tex2D(s_image, offset + I.tc2 * w);
half4 s2 = tex2D(s_image, offset + I.tc3 * w);
half4 s3 = tex2D(s_image, offset + I.tc4 * w);
return (s0 + s1 + s2 + s3)/4.h;
}
Examples
Example 1: Phong modelThibieroz03
G-Buffer structure:
- Pixel position
- World space position of the pixel
- R16G16B16A16 FLOAT
- Pixel Normal vector
- World space normalized normal vector
- Choice:
- Model space: Simplest.
- Tangent space
- R10G10B10A2 / R8G8B8A8 INT / FLOAT
- Pixel diffuse color
- R8G8B8A8 FLOAT
-
References:
m4x4 dst, src0, src1: multiplies a 4-component vector by a 4x4 matrix.src0is a 4-component vector,src1is a 4x4 matrix (dst = mul(src1, src0)(ifsrc0is column vector))mov dst, src: move floating-point data between registers
PreLightPass.vs
;-------------------------------------------------------------------
; Constants specified by the app
; c0-c3 = Global transformation matrix (World*View*Projection)
; c4-c7 = World transformation matrix
;
; Vertex components
; v0 = Vertex Position
; v1, v2, v3 = Inverse of tangent space vectors
; v4 = 2D texture coordinates (model coordinates)
;-------------------------------------------------------------------
vs_2_0
dcl_position v0 ; Vertex position
dcl_binormal v1 ; Transposed binormal
dcl_tangent v2 ; Transposed tangent
dcl_normal v3 ; Transposed normal
dcl_texcoord v4 ; Texture coordinates for diffuse and normal map
; Vertex transformation
m4x4 oPos, v0, c0 ; Transform vertices by WVP matrix
; Model texture coordinates
mov oT0.xy, v4.xy ; Simply copy texture coordinates
; World space coordinates
m4x3 oT1.xyz, v0, c4 ; Transform vertices by world matrix (no w
; needed)
; Inverse (transpose) of tangent space vectors
mov oT2.xyz, v1
mov oT3.xyz, v2
mov oT4.xyz, v3 ; Pass in transposed tangent space vectors
cbuffer ConstantBuffer : register(b0)
{
float4x4 WVP; // Global transformation matrix
float4x4 World; // World transformation matrix
}
struct VSInput
{
float4 Position : POSITION; // Vertex position
float3 Binormal : BINORMAL; // Inverse of tangent space vectors >> Transposed binormal
float3 Tangent : TANGENT; // Inverse of tangent space vectors >> Transposed tangent
float4 Normal : NORMAL; // Inverse of tangent space vectors >> Transposed normal
float2 TexCoord : TEXCOORD0; // 2D texture coordinates for diffuse and normal map (model coordinates)
};
struct VSOutput
{
float4 Position : SV_Position;
float3 WorldPos : WorldPos;
float3 Binormal : Binormal;
float3 Tangent : Tangent;
float3 Normal : Normal;
float2 TexCoord : TexCoord0;
};
VSOutput main(VSInput vsInput)
{
VSOutput vsOutput;
// Vertex transformation
vsOutput.Position = mul(WVP, vsInput.Position); // Transform vertices by WVP matrix
// Model texture coordinates
vsOutput.TexCoord = vsInput.TexCoord; // Simply copy texture coordinates
// World space coordinates
vsOutput.WorldPos = mul(float3x3(World), vsInput.Position.xyz); // Transform vertices by world matrix (no w needed)
// Inverse(transpose) of tangent space vectors
vsOutput.Binormal = vsInput.Binormal;
vsOutput.Tangent = vsInput.Tangent;
vsOutput.Normal = vsInput.Normal; // Pass in transposed tangent space vectors
return vsOutput;
}
def dst, fValue1, fValue2, fValue3, fValue4: Defines pixel shader floating-point constants.fValue1tofValue4are floating=point valuestexld dst, src0, src1: Sample a texture at a particular sampler, using provided texture coordinates.src0is a source register that provides the texture coordinates for the texture sample.src1identifies the Sampler where # specifies which texture sampler number to sample.mad dst, src0, src1, src2: Multiply and add instruction. Sets the destination register to(src0 * src1) + src2.dp3 dst, src0, src1: Computes the three-component dot product of the source registers.
PreLightPass.ps
;-------------------------------------------------------------------
; Constants specified by the app
; c0-c3 = World transformation matrix for model
;-------------------------------------------------------------------
ps_2_0
; Samplers
dcl_2d s0 ; Diffuse map
dcl_2d s1 ; Normal map
; Texture coordinates
dcl t0.xy ; Texture coordinates for diffuse and normal map
dcl t1.xyz ; World-space position
dcl t2.xyz ; Binormal
dcl t3.xyz ; Tangent
dcl t4.xyz ; Normal (Transposed tangent space vectors)
; Constants
def c30, 1.0, 2.0, 0.0, 0.0
def c31, 0.2, 0.5, 1.0, 1.0
; Texture sampling
texld r2, t0, s1 ; r2 = Normal vector from normal map
texld r3, t0, s0 ; r3 = Color from diffuse map
; Store world-space coordinates into MRT#0
mov oC0, t1 ; Store pixel position in MRT#0
; Convert normal to signed vector
mad r2, r2, c30.g, -c30.r ; r2 = 2*(r2 - 0.5)
; Transform normal vector from tangent space to model space
dp3 r4.x, r2, t2
dp3 r4.y, r2, t3
dp3 r4.z, r2, t4 ; r4.xyz = model space normal
; Transform model space normal vector to world space. Note that only
; the rotation part of the world matrix is needed.
; This step is not required for static models if their
; original model space orientation matches their orientation
; in world space. This would save 3 instructions.
m4x3 r1.xyz, r4, c0
; Convert normal vector to fixed point
; This is not required if the destination MRT is float or signed
mad r1, r1, c31.g, c31.g ; r1 = 0.5*(r1 + 0.5)
; Store world-space normal into MRT#1
mov oC1, r1
; Store diffuse color into MRT#2
mov oC2, r3
cbuffer ConstantBuffer : register(b0)
{
float4x4 World;
}
// Samplers
Texture2D<float3> g_DiffuseMap : register(t0); // Diffuse map
Texture2D<float3> g_NormalMap : register(t1); // Normal map
SamplerState g_Sampler : register(s0);
struct PSInput
{
float4 Position : SV_Position;
float3 WorldPos : WorldPos; // World-space position
float3 Binormal : Binormal; // Binormal
float3 Tangent : Tangent; // Tangent
float3 Normal : Normal; // Normal (Transposed tangent space vectors)
float2 TexCoord : TexCoord0; // Texture Coordinates for diffuse and normal map
};
struct Mrt
{
float3 WorldPos;
float3 WorldNormal;
float3 Albedo;
}
Mrt main(PSInput psInput)
{
Mrt mrt;
// Texture sampling
float3 normal = g_NormalMap.Sample(g_Sampler, psInput.TexCoord); // Normal vector from normal map
float3 albedo = g_DiffuseMap.Sample(g_Sampler, psInput.TexCoord); // Color from diffuse map
// Store world-space coordinates into MRT#0
mrt.WorldPos = psInput.WorldPos;
// Convert normal to signed vector if needed
// normal = 2.0 * (normal - 0.5);
// Transform normal vector from tangent space to model space
float3 modelNormal = float3(dot(normal, psInput.Binormal), dot(normal, psInput.Tangent), dot(normal, psInput.Normal));
// Transform model space normal vector to world space. Note that only the rotation part of the world matrix is needed.
// This step is not required for static models if their original model space orientation matches their orientation in world space.
// This would save 3 instructions.
float3 worldNormal = mul(float3x3(World), modelWorld);
// Convert normal vector to fixed point
// This is not required if the destination MRT is float or signed
// worldNormal = 0.5 * (worldNormal + 0.5)
// Store world-space normal into MRT#1
mrt.WorldNormal = worldNormal;
// Store diffuse color into MRT#2
mrt.Albedo = albedo;
return mrt;
}
rcp dst, src: Computes the reciprocal of the source scalar
LightPass.ps
;-------------------------------------------------------------------
; Constants specified by the app
; c0 : light position in world space
; c8 : camera position in world space
; c22: c22.a = 1/(light max range), c22.rgb = 1.0f
;-------------------------------------------------------------------
ps_2_0
; Samplers
dcl_2d s0 ; MRT#0 = Pixel position in world space
dcl_2d s1 ; MRT#1 = Pixel normal vector
dcl_2d s2 ; MRT#2 = Pixel diffuse color
dcl_2d s3 ; Falloff texture
dcl_cube s4 ; Cube normalization texture map
; Texture coordinates
dcl t0.xy ; Quad screen-space texture coordinates
; Constants
def c20, 0.5, 2.0, -2.0, 1.0
def c21, 8.0, -0.75, 4.0, 0.0
; Retrieve property buffer data from MRT textures
texld r0, t0, s0 ; r0.xyz = Pixel world space position
texld r2, t0, s1 ; r2.xyz = Pixel normal vector
texld r3, t0, s2 ; r3.rgb = Pixel color
; Convert normal to signed vector
; This is not required if the normal vector was stored in a signed
; or float format
mad r2, r2, c20.y, -c20.w ; r2 = 2*(r2 - 1)
; Calculate pixel-to-light vector
sub r1.xyz, c0, r0 ; r1 = Lpos - Vpos
mov r1.w, c20.w ; Set r1.w to 1.0
nrm r4, r1 ; Normalize vector (r4.w = 1.0/distance)
; Compute diffuse intensity
dp3 r5.w, r4, r2 ; r5.w = (N.L)
; FallOff
rcp r6, r4.w ; r6 = 1/(1/distance) = distance
mul r6, r6, c22.a ; Divide by light max range
texld r6, r6, s3 ; Sample falloff texture
; Compute halfway vector
sub r1.xyz, c8, r0 ; Compute view vector V (pixel to camera)
texld r1, r1, s4 ; Normalized vector with cube map
mad r1, r1, c20.y, -c20.w ; Convert vector to signed format
add r1, r1, r4 ; Add view and light vector
texld r1, r1, s4 ; Normalize half angle vector with cube map
mad r1, r1, c20.y, -c20.w ; Convert to signed format
; Compute specular intensity
dp3_sat r1.w, r1, r2 ; r1.w = sat(H.N)
pow r1.w, r1.w, c21.r ; r1.w = (H.N)^8
; Set specular to 0 if pixel normal is not facing the light
cmp r1.w, r5.w, r1.w, c21.w ; r1.w = ( (N.L)>=0 ) ? (H.N)^8 : 0
; Output final color
mad r0, r3, r5.w, r1.w ; Modulate diffuse color and diffuse
; intensity and add specular
mul r0, r0, r6 ; Modulate with falloff
mov oC0, r0 ; Output final color
cbuffer ConstantBuffer : register(b0)
{
float4 LightPos; // Light position in world space
float4 CameraPos; // Camera position in world space
float LightAttenuation; // 1.0 / (light max range)
}
// Samplers
Texture2D<float3> g_WorldPos : register(t0);
Texture2D<float3> g_WorldNormal : register(t1);
Texture2D<float3> g_Albedo : register(t2);
Texture2D<float3> g_Falloff : register(t3);
TextureCube<float4> g_Normalization : register(t4);
SamplerState g_DefaultSampler : register(s0);
SamplerState g_CubeSampler : register(s1);
// Texture coordinates
struct PSInput
{
float4 Position : SV_Position;
float2 TexCoord : TexCoord0; // Quad screen-space texture coordinates
};
float4 main(PSInput psInput) : SV_Target
{
// Retrieve property buffer data from MRT textures
float3 worldPos = g_WorldPos.Sample(g_DefaultSampler, psInput.TexCoord); // pixel world space position
float3 worldNormal = g_WorldNormal.Sample(g_DefaultSampler, psInput.TexCoord); // pixel normal vector
float3 albedo = g_Albedo.Sample(g_DefaultSampler, psInput.TexCoord); // pixel color
// Convert normal to signed vector
// This is not required if the normal was stored in a signed or float format
// worldNormal = 2.0 * (worldNormal - 1.0)
// Calculate pixel-to-light vector
float4 lightDir = normalize(float4(LightPos - worldPos, 1.0)); // lightDir.w = 1.0 / distance
// Compute diffuse intensity
float diffuseIntensity = dot(lightDir, worldNormal); // diffuse intensity = (N dot L)
// Fall off
float fallOff = 1.0 / lightDir.w; // 1.0 / (1.0 / distance) = distance
fallOff *= LightAttenuation; // Divide by light max range
fallOff = g_Falloff.Sample(g_DefaultSampler, float2(fallOff, fallOff)); // Sample falloff texture
// Compute halfway vector
float4 viewDir = CameraPos - worldPos; // Compute view vector V (pixel to camera)
viewDir = g_Normalization.Sample(g_CubeSampler, viewDir.xyz); // Normalized vector with cube map
// Convert vector to signed format
// viewDir = 2.0 * (viewDir - 1.0);
// Compute specular intensity
float specularIntensity = pow(saturate(dot(viewDir, worldNormal)), 8.0); // (H dot N)^8
// Set specular to 0 if pixel normal is not facing the light
specularIntensity = (diffuseIntensity >= 0.0) ? specularIntensity : 0.0;
// Output final color
float4 color = albedo * diffuseIntensity + specularIntensity; // modulate diffuse color and diffuse intensity and add specular
color *= fallOff; // Modulate with falloff
return color; // Output final color
}
Example 2: AMD GDC 2011Thibieroz11
- Light Pre-pass
- Render Normals
- 1st geometry pass results in normal(and depth) buffer
- Uses a single color RT
- No MRT required
- 1st geometry pass results in normal(and depth) buffer
- Lighting Accumulation
- Perform all lighting calculation into light buffer
- Use normal and depth buffer as input textures
- Render geometries enclosing light area
- Write (LightColor * N.L * Attenuation) in RGB, specular in A
- Perform all lighting calculation into light buffer
- Combine lighting with materials
- 2nd geometry pass using light buffer as input
- Fetch geometry material
- Combine with light data
- Advantages
- One material fetch per pixel regardless of number of lights
- Disadvantages
- Two scene geometry passes required
- Unique lighting model
- Advantages
- 2nd geometry pass using light buffer as input
- Render Normals
- Light Volume Rendering
- Early Z culling Optimizations
- When camera is inside the light volume
- Set Z Mode = GREATER
- Render volume’s back faces
- Only samples fully inside the volume get shaded
- Optimal use of early Z culling
- No need for stencil
- High efficiency
- Previous optimization does not work if camera is outside volume
- Back faces also pass the Z=GREATER test for objects in front of volume
- Alternatively, when camera is outside the light volume:
- Set Z Mode = LESSEQUAL
- Render volume’s front faces
- But generates wasted processing for objects behind the volume
- Stencil can be used to mark samples inside the light volume
- Render volume with stencil-only pass:
- Clear stencil to 0
- Set Z Mode = LESSEQUAL
- If depth test fails:
- Increment stencil for back faces
- Decrement stencil for front faces
- Render some geometry where stencil != 0
- When camera is inside the light volume
- Early Z culling Optimizations
Example 3: AnKi 3D EngineCharitos19
- Clustered Deferred Shading
- Bin various primitives into a number of clusters
- Happens in the CPU
- Point lights
- Spot lights
- Decals
- Fog density probes
- Reflection probes
- Diffuse GI probes
- Bin various primitives into a number of clusters
Passs:
- Depth pre-pass
- GBuffer pass
| MRTs | R | G | B | A |
| RT 0 | Albedo.R R8U | Albedo.G G8U | Albedo.B B8U | Subsurface term A8U | RT 1 | Roughness R8U | Metallic G8U | Fresnel term B8U | Emission scaling A8U | </tr>
| RT 2 | WS Normal.X R10U_PACK32 | WS Normal.Y G10U_PACK32 | Emission B10U_PACK32 | Sign of the Normal's Z A2U_PACK32 |
| RT 3 | Velocity R16S | Velocity G16S |
- Volumetric lighting accumulation
- Compute job that calculatese the lighting for eaach cell and the fog density
- Every compute invocation operates on a single cluster
- Each invocation a random point inside the cluster will be chosen and the lighting of each light will be accumulated to compute the final result
- Final result is stored into a 3D texture
- Light shading, forward shading, and fog
- Light shading
- Fullscreen(triangle) draw that unpacks the GBuffer and iterates the lights of the affected cluster
- Light shading
Example 4: The SurgeHammer18
- Clustered Deferred Rendering
- Volumetric Lighting
| MRTs | R | G | B | A |
| RT 0 | Albedo.R R8 | Albedo.G G8 | Albedo.B B8 | Material ID |
| RT 1 | VS Normal.X R10 | VS Normal.Y G10 | VS Normal.Z B10 | A2 | RT 2 | Roughness R8 | Metalness G8 | Occlusion B8 | (shared) A8 | </tr>
| RT 3 | Motion Vectors X R16 | Motion Vectors Y G16 |
PBR:
- Material ID indexes directly into StructuredBuffer to query per=material data
- Save G-Buffer space
- (shared) - per pixel context dependent
- mutual exclusive material data
- based on per-material data
- Emissive mask
- Defines whether or not to interpret albedo as emissive
- Emissive combined in final “combine” pass
- Effectively saves dedicated emissive channel
- Translucency
Clustered Deferred Rendering:
- Switch from rasterization-based light volume rendering to full (async) compute-based approach
- Low CPU overhead
- Light culling runs entirely on GPU
- Filling a buffer with light infos instead of dispatching thousands of drawcalls
- Advantages on GPU
- No need to fetch G-Buffer for every light
- Async Compute: Lighting runs in parallel to shadow rendering (at least on consoles)
- But: many more optimizations necessary to get better performance
- Low CPU overhead
- Could render environment probes in the same pass
- Environment probes are still clustered but rendered in a separate (pixeshader) pass together with SSR
- Divide view frustum into a 3D grid
- 16 x 8 x 24
- Culling: Assignn lights to grid cells
- Upload light culling info to GPU (StructuredBuffer with Position, AABB, etc.)
- Create list of light indices for each cell (single large uint buffer)
- Dispatching lighting compute shader
- In fact we dispatch twice: unshadowed and shadowed lights
- Unshadowed can run in parallel with shadowmap generation
- Can use cluster information also for forward rendering
- We do this for our lit transparent objects
- Simply compute grid cell index for a position and query light list
Example 5: Rainbow Six SiegeElMansouri16
- Single Frame:
- GPU:
- Graphics Pipeline + Async Pipeline
- Average 5ms spent on geometry rendering
- Heavy us of culling
- Shadow caching
- Average 5ms spent on lighting (SSR included)
- Checkerboard rendering helps
- SSAO & SSR ray trace done in async
- CPU:
- 10ms avg on the critical path
- All passes and tasks able to fork and join to minimize critical path
- Shadow caching
- Max 4ms linear spent on opaque pass
- Material based draw call system
- 10ms avg on the critical path
- GPU:
- Opaque rendering:
- First person rendering
- GBuffer, Depth buffer
- 400 best occluders to depth buffer
- Generate Hi-Z Buffer
- Opaque culling & rendering
- Hierarchical z-buffer used for culling
- First person rendering
- Lighting
- Uses a clustered structure on the frustum:
- 32 x 32 pixels based tile
- Z exponential distribution
- Hierarchical culling of light volume to fill the structure
- Local cubemaps regarded as lights
- Shadows, cubemaps and gobos reside in textures arrays
- Deferred uses pre-resolved shadow texture array
- Forward uses shadows depth buffer array
- Uses a clustered structure on the frustum:
| MRTs | R | G | B | A |
| RT 0 | Emissive.R R11 | Emissive.G G11 | Emissive.B B10 | |
| RT 1 | Normal.X R10 | Normal.Y G10 | Normal.Z B10 | A2 |
| RT 2 | Albedo.R R8 | Albedo.G G8 | Albedo.B B8 | Material Masking A8 | RT 3 | Material Properties R8 | Material Properties G8 | Material Properties B8 | Material Properties A8 | </tr>
Example 6: Uncharted 4ElGarawany16
- 16 bits-per-pixel unsigned buffers
| GBuffers | R | G | B | A |
| GBuffer 0 | R G |
B Spec |
Normal.X Normal.Y |
iblUseParent, Normal Extra Roughness |
| GBuffer 1 | Ambient Translucency Sun Shadow High Spec Occlusion |
Heightmap Shadowing Sun Shadow Low Metallic |
Dominant Direction X Dominant Direction Y |
AO Extra Material Mask Sheen Thin Wall Translucency |
| GBuffer 2 (optional) | Used by more complicated materials | |||
- Using a material ID(bitmask) texture
- 12-bits compressed into 8-bits
Example 7: CryENGINE 3Kaplanyan10
- Indirect Lighting
- Ambient term
- Tagged ambient areas
- Local cubemaps
- Local deferred lights
- Diffuse Indirect Lighting from LPVs
- SSAO
- Direct lighting
- All direct light sources, with and without shadows
- GBuffer. The smaller the better
- Minimal G-Buffer layout: 64 bits / pixel
- RT0: Depth 24bpp + Stencil 8bpp
- RT1: Normals 24bpp + Glossiness 8bpp
- Glossiness is non-deferrable
- Required at lighting accumulation pass
- Specular is non-accumulative otherwise
- Glossiness is non-deferrable
- Stencil to mark objects in lighting groups
- Portals / indoors
- Custom environment reflections
- Different ambient / indirect lighting
- Problems:
- Only Phong BRDF (normal + glossiness)
- No aniso materials
- Normals at 24bpp are too quantized
- Lighting is banded / of low quality
- Use baked normal map
- Only Phong BRDF (normal + glossiness)
- Minimal G-Buffer layout: 64 bits / pixel
Example 8: UnityGolubev18
- Optimize with both Tile and Cluster approaches
- Goal
- Focus on removing false positives
- Ex: Narrow shadow casting spot lights
- False positives are more expensive in lighting pass
- Light culling execute async during shadow rendering
- Deferred lighting pass is not running async
- Move cost where it can be hidden
- High register pressure in lighting pass
- Focus on removing false positives
- Hierarchical approach
- Find screen-space AABB for each visible light
- Big tile 64 x 64 prepass
- Coarse intersection test
- Use AABBs for initial early out (2D no depth)
- Follow up with exact intersection test between tile and convex hull
- Use bounding spheres as an extra testing criteria
- Build Tile or Cluster Light list
- Narrow intersection test
Forward+HaradaMcKeeYang13
- Z prepass
- Reduces the pixel overdraws of the final shading step
- Light culling
- Calculates the list of lights affecting a pixel
- Final shading
- Shades the entire surface
- Any lights in a scene have to be accessible from shaders rather than binding some subset of lights for each objects
Light Culling
- Split the screen into tiles
- Light indices are calculated on a per-tile basis
Implementation and Optimization
- Computation is done on a by-tile basis
- Execute a thread group for a tile
- CS for light culling is executed as a two-dimensional (2D) work group
Pseudo-code:
GET_GROUP_IDX: thread group index in X direction (SV_GroupID)GET_GROUP_IDY: thread group index in Y direction (SV_GroupID)GET_GLOBAL_IDX: global thread index in X direction (SV_DispatchThreadID)GET_GLOBAL_IDY: global thread index in X direction (SV_DispatchThreadID)GET_LOCAL_IDX: local thread index in X direction (SV_GroupThreadID)-
GET_LOCAL_IDY: local thread index in X direction (SV_GroupThreadID) - The first step is computation of the frustum of a tile in view space
- Calculate the view-space coordinates of the four corner points of the tile
float4 frustum[4];
{ // construct frustum
float4 v[4];
v[0] = projToView(8 * GET_GROUP_IDX, 8 * GET_GROUP_IDY, 1.f);
v[1] = projToView(8 * (GET_GROUP_IDX + 1), 8 * GET_GROUP_IDY, 1.f);
v[2] = projToView(8 * (GET_GROUP_IDX + 1), 8 * (GET_GROUP_IDY + 1), 1.f);
v[3] = projToView(8 * GET_GROUP_IDX, 8 * (GET_GROUP_IDY + 1), 1.f);
float4 o = make_float4(0.f, 0.f, 0.f, 0.f);
for (int i = 0; i < 4; ++i)
{
frustum[i] = createEquation(o, v[i], v[(i + 1) & 3]);
}
}
projToView()is a function that takes screen-space pixel indices and depth value and returns coordinates in view spacecreateEquation()creates a plane equation from three vertex positions- We can clip the frustum by using the max/min depth values from the depth buffer created in the depth prepass.
float depth = depthIn.Load(uint3(GET_GLOBAL_IDX, GET_GLOBAL_IDY, 0));
float4 viewPos = projToView(GET_GLOBAL_IDX, GET_GLOBAL_IDY, depth);
int lIdx = GET_LOCAL_IDX + GET_LOCAL_IDY * 8;
{ // Calculate bound
if (lIdx == 0) // Initialize
{
ldsZMax = 0;
ldsZMin = 0xffffffff;
}
GroupMemoryBarrierWithGroupSync();
u32 z = asuint(viewPos.z);
if (depth != 1.f)
{
AtomMax(ldsZMax, z);
AtomMin(ldsZMin, z);
}
GroupMemoryBarrierWithGroupSync();
maxZ = asfloat(ldsZMax);
minZ = asfloat(ldsZMin);
}
ldsZMax,ldsZMinstore max/min z coordinates, which are bounds of a frustum in the z direction, in shared memory
MiniEngine version:
// Read all depth values for this tile and compute the tile min and max values
for (uint dx = GTid.x; dx < WORK_GROUP_SIZE_X; dx += 8)
{
for (uint dy = GTid.y; dy < WORK_GROUP_SIZE_Y; dy += 8)
{
uint2 DTid = Gid * uint2(WORK_GROUP_SIZE_X, WORK_GROUP_SIZE_Y) + uint2(dx, dy);
// If pixel coordinates are in bounds...
if (DTid.x < ViewportWidth && DTid.y < ViewportHeight)
{
// Load and compare depth
uint depthUInt = asuint(depthTex[DTid.xy]);
InterlockedMin(minDepthUInt, depthUInt);
InterlockedMax(maxDepthUInt, depthUInt);
}
}
}
GroupMemoryBarrierWithGroupSync();
- We are using 8 x 8 for the size of a thread group
- 64 lights are processed in parallel
for (int i = 0; i < nBodies; i += 64)
{
int il = lIdx + i;
if (il < nBodies)
{
if (overlaps(frustum, gLightGeometry[i]))
{
appendLightToList(il);
}
}
}
overlaps(): chekcs light-geometry overlap against a frustum using the separating axis theorem- If a light is overlapping the frustum, the light index is stored to the list of the overlapping lights in
appendLightToList()
- If a light is overlapping the frustum, the light index is stored to the list of the overlapping lights in
- A tile is computed by a thread group, and so we can use shared memory for the first level storage
- Light index storage and counter for the storage is allocated as follows:
groupshared u32 ldsLightIdx[LIGHT_CAPACITY];
groupshared u32 ldsLightIdxCounter;
void appendLightToList(int i)
{
u32 dstIdx = 0;
InterlockedAdd(ldsLightIdxCounter, 1, dstIdx);
if (dstIdx < LIGHT_CAPACITY)
{
ldsLightIdx[dstIdx] = i;
}
}
MiniEngine version:
groupshared uint tileLightCountSphere;
groupshared uint tileLightCountCone;
groupshared uint tileLightCountConeShadowed;
groupshared uint tileLightIndicesSphere[MAX_LIGHTS];
groupshared uint tileLightIndicesCone[MAX_LIGHTS];
groupshared uint tileLightIndicesConeShadowed[MAX_LIGHTS];
// find set of lights that overlap this tile
for (uint lightIndex = GI; lightIndex < MAX_LIGHTS; lightIndex += 64)
{
LightData lightData = lightBuffer[lightIndex];
float3 lightWorldPos = lightData.pos;
float lightCullRadius = sqrt(lightData.radiusSq);
bool overlapping = true;
for (int p = 0; p < 6; p++)
{
float d = dot(lightWorldPos, frustumPlanes[p].xyz) + frustumPlanes[p].w;
if (d < -lightCullRadius)
{
overlapping = false;
}
}
if (!overlapping)
continue;
uint slot;
switch (lightData.type)
{
case 0: // sphere
InterlockedAdd(tileLightCountSphere, 1, slot);
tileLightIndicesSphere[slot] = lightIndex;
break;
case 1: // cone
InterlockedAdd(tileLightCountCone, 1, slot);
tileLightIndicesCone[slot] = lightIndex;
break;
case 2: // cone w/ shadow map
InterlockedAdd(tileLightCountConeShadowed, 1, slot);
tileLightIndicesConeShadowed[slot] = lightIndex;
break;
}
// update bitmask
InterlockedOr(tileLightBitMask[lightIndex / 32], 1 << (lightIndex % 32));
}
GroupMemoryBarrierWithGroupSync();
- Now indices of lights overlapping that frustum are collected in the shared memory
- We have to write these to the global memory
- For the storage of light indices in the global memory, we allocated two buffers:
gLightIdx: memory pool for the indices- First reserve memory here
- Done by an atomic operation to
gLightIdxCounterusing a thread in the thread group
- Done by an atomic operation to
- First reserve memory here
gLightIdxCounter: memory counter for the memory pool
- Once a memory offset is obtained, we just fill the light indices to the assigned contiguous memory of
gLightIdxusing all the threads in a thread group
{ // Write back
u32 startOffset = 0;
if (lIdx == 0)
{ // Reserve memory
if (ldsLightIdxCounter != 0)
{
InterlockedAdd(gLightIdxCounter, ldsLightIdxCounter, startOffset);
}
ptLowerBound[tileIdx] = startOffset;
ldsLightIdxStart = startOffset;
}
GroupMemoryBarrierWithGroupSync();
startOffset = ldsLightIdxStart;
for (int i = lIdx; i < ldsLightIdxCounter; i += 64)
{
gLightIdx[startOffset + i] = ldsLightIdx[i];
}
}
MiniEngine version:
if (GI == 0)
{
uint lightCount =
((tileLightCountSphere & 0xff) << 0) |
((tileLightCountCone & 0xff) << 8) |
((tileLightCountConeShadowed & 0xff) << 16);
lightGrid.Store(tileOffset + 0, lightCount);
uint storeOffset = tileOffset + 4;
uint n;
for (n = 0; n < tileLightCountSphere; n++)
{
lightGrid.Store(storeOffset, tileLightIndicesSphere[n]);
storeOffset += 4;
}
for (n = 0; n < tileLightCountCone; n++)
{
lightGrid.Store(storeOffset, tileLightIndicesCone[n]);
storeOffset += 4;
}
for (n = 0; n < tileLightCountConeShadowed; n++)
{
lightGrid.Store(storeOffset, tileLightIndicesConeShadowed[n]);
storeOffset += 4;
}
lightGridBitMask.Store4(tileIndex * 16, tileLightBitMask);
}
Shading
- With UAV support, per-material instance information can be stored and accessed in linear structured buffers passed to material shaders
Tiled Shading
Light Pre-Pass Renderer
- Store depth / normalEngelShaderX709
- Normal: R8G8B8A8
- WS Normal will be of better quality when stored in spherical coordinates
- Normal: R8G8B8A8
- Store light properties of all lights in a light bufferEngelShaderX709
- Only light properties (no shadows, reflections, etc.)
- Light dependant terms need to be stored by their locality in space by applying the diffuse term N.L and the attenuation factor to all of them
- Typical L-Buffer:
- Σi N · Li * DiffuseRed * Attenuationi
- Σi N · Li * DiffuseGreen * Attenuationi
- Σi N · Li * DiffuseBlue * Attenuationi
- Σi N · Li * (N · Hi)n * Attenuationi
- If the specular term can be separated in a later rendering pass, a dedicated material shininess value can be applied
- (Σi (N · Hi)n)mn
- If the specular term can be separated in a later rendering pass, a dedicated material shininess value can be applied
- Applying a material shiniess value to the specular reflection can be done in several ways
- Similar to a deferred renderer, a material specular shininess can be stored in the normal / depth buffer (stencil area)
- Moving into a different color space that reuses some of the ideas here to achieve a tighter packed render target
- A separate term can be stored to reconstruct the specular term in a later render pass
- Σi N · Li * DiffuseRed * Attenuationi
- Σi N · Li * DiffuseGreen * Attenuationi
- Σi N · Li * DiffuseBlue * Attenuationi
- Σi N · Li * (N · Hi)n * Attenuationi
- Σi N · Li * Attenuationi
- With the additional term, we can reconstruct the specular term:
- (Σi N · Li * (N · Hi)n * Attenuationi) / (Σi N · Li * Attenuationi)
- The result of this equation can be used to apply a material shininess value
- With the additional term, we can reconstruct the specular term:
- The diffuse term stored in the first three channels of the light buffer can be converted to luminance and then used to reconstruct the specular reflection term
- The common rules for constructing a specular term can be bended by creating a new term that fits better into this renderer design
Comparison and Conclusion
|Forward / Z Pre-Pass Renderer|Light Pre-Pass Renderer| |—|—| |Lots of geometry throughput| | |Need to split up geometry following light distribution| | |Dependent texture look-up and lights are not fully dynamic| | EngelSiggraph09
|Deferred Renderer|Light Pre-Pass Renderer|
|—|—|
|Lights are independent from geometry| |
|Geometry pass stores all material and light properties|Geometry pass fills up normal and depth buffer,
Lighting pass stores light properties in light buffer|
|Only one geometry pass for the main view|(Version A) Second geometry buffer fetches light buffer and apply different material terms per surface by reconstructing the lighting equation
(Version B) Ambient + Resolve(MSAA) pass fetches light buffer and uses its content as diffuse / specular content and add the ambient term while resolving into the main buffer|
|Lights are blit and therefore only limited by memory bandwidth||
|Memory bandwidth| |
|Recalculate full lighting equation for every light| |
|Limited material representation in G-Buffer| |
|MSAA difficult compared to Forward renderer| |
EngelSiggraph09
- Compared to a deferred rendererEngelShaderX709
- Offers more flexibility regarding material implementations
- Reads memory bandwidth is lower
- Using MSAA can be more efficient
- Renders all geometry for the main view twice
- Compared to a Z pre-pass rendererEngelShaderX709
- Offers less flexibility but a flexible and fast multi-light solution
- Implementation (D3D11)EngelSiggraph09
- GS bounding box
- construct bounding box in geometry shader
- implement lighting with the compute shader
- Balance quality / performance
- Stop rendering dynamic lights after a certain range for example 40 meters and render glow cards instead
- Use smaller light buffer for distant lights and scale up
- GS bounding box
Clustered Shading
Cluster Deferred Shading AlgorithmOlssonBilleterAssarsson12
- Render scene to G-Buffers
- Cluster assignment
- Find unique clusters
- Assign lights to clusters
- Shade samples
Cluster Assignment
- Goal of the cluster assignment:
- Compute an integer cluster key for a given view sample from the information available G-Buffer
- position, normal (optional)
- Compute an integer cluster key for a given view sample from the information available G-Buffer
- Subdivide the view frustum along x, y, z-axis in view space (or NDC)
- Due to the non-linear nature of NDC, clusters close to the near plane becomes very thin, where as those towards the far plane becomes very long
- Uniform subdivision in view space produces the opposite artifact
- Space the divisions exponentially
- neark = neark - 1 + hk - 1
- near0 = near (first subdivision)
- h0 = (2 near tan θ) / Sy (Sy = number of subdivisions in the Y direction, FoV = 2θ)
- neark = near(1 + (2 tan θ) / Sy)k
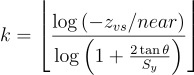
- Cluster key tuple
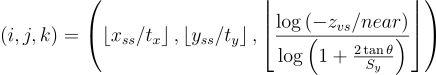
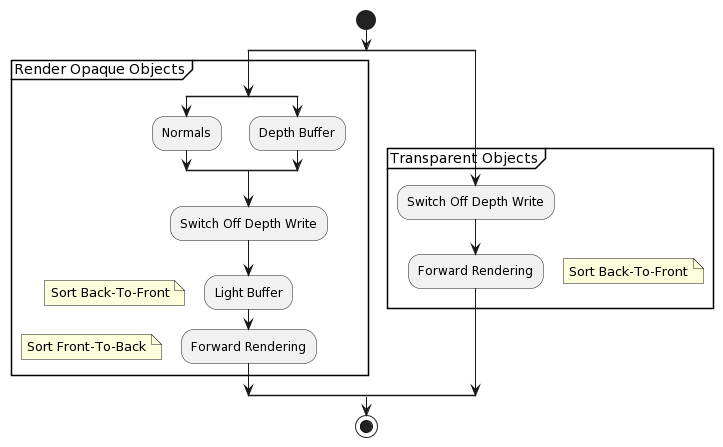
Finding Unique Clusters
@startuml
start
split
group Render Opaque Objects
split
:Normals;
split again
:Depth Buffer;
end split
:Switch Off Depth Write;
:Light Buffer;
floating note left: Sort Back-To-Front
:Forward Rendering;
floating note left: Sort Front-To-Back
end group
split again
group Transparent Objects
:Switch Off Depth Write;
:Forward Rendering;
floating note right: Sort Back-To-Front
end group
end split
stop
@enduml
k = \left \lfloor \frac{\log{\left(-z_{vs}/near\right)}}{\log{\left(1 + \frac{2 \tan{\theta}}{S_y} \right )}} \right \rfloor
\left(i, j, k \right ) = \left(\left \lfloor x_{ss}/t_x \right \rfloor, \left \lfloor y_{ss}/t_y \right \rfloor, \left \lfloor \frac{\log{\left(-z_{vs}/near\right)}}{\log{\left(1 + \frac{2 \tan{\theta}}{S_y} \right )}} \right \rfloor \right )