실무에서의 ReSTIR (2022.09.17)
공부 노트
논문들
2020년에 SIGGRAPH에 나온 Spatiotemporal reservoir resampling for real-time ray tracing with dynamic direct lighting 논문으로부터 ReSTIR 붐이 시작되었는데, 해당 기술을 적용한 여러 논문을 읽고 정리해본 노트다.
참고한 논문들:
- Spatiotemporal reservoir resampling for real-time ray tracing with dynamic direct lighting. Benedikt Bitterli, Chris Wyman, Matt Pharr, Peter Shirley, Aaron Lefohn, Wojciech Jarosz. ACM ToG. SIGGRAPH. 2020.07.19.
- 일명 ReSTIR 논문
- 블로그 정리본
- Part 1: Rendering Games With Millions of Ray Traced Lights. 2021.01.12.
- Part 2: Light Resampling In Practice with RTXDI. 2021.01.12.
- RTXDI: Details on Achieving Real Time Performance. Chris Wyman. Microsoft Game Stack Live. 2021. 04.21.
- ReSTIR GI: Path Resampling for Real-Time Path Tracing. Yaobin Ouyang, Shiqiu Liu, Markus Kettunen, Matt Pharr, Jacopo Pantaleoni. CGF. HPG. 2021.06.24.
- 일명 ReSTIR GI 논문
- 블로그 정리본
- Rearchitecturing Spatiotemporal Resampling for Production. Chris Wyman, Alexey Panteleev. HPG. 2021.07.06.
- 일명 RTXDI 논문
- 블로그 정리본
- Rendering Many Lights with Grid-Based Reservoirs. 2021.08.04.
- 일명 ReGIR 논문
- 블로그 정리본
- ReSTIR Meets Surfel Lighting Breakdown. 2021.11.23.
- Fast Volume Rendering with Spatiotemporal Reservoir Resampling. Daqi Lin, Chris Wyman, Cem Yuksel. ACM ToG. SIGGRAPH Asia. 2021.11.30.
- 일명 Volumetric ReSTIR 논문
- 블로그 정리본
- Dynamic Diffuse Global Illumination Resampling. Zander Majercik, Thomas Müller, Alexander Keller, Derek Nowrouzezahrai, Morgan McGuire. CGF. EGSR. 2021. 12.06.
- 일명 DDGI ReSTIR 논문
- World-Space Spatiotemporal Reservoir Reuse for Ray-Traced Global Illumination. Guillaume Boissé. SIGGRAPH Asia. 2021.12.14.
- 일명 WS ReSTIR 논문
- 블로그 정리본
- How to add thousands of lights to your renderer and not die in the process. 2022.03.13.
- ReSTIR GI for Specular Bounces. 2022.04.12.
- ReSTIR El-Cheapo. 2022.05.04.
- GI Overview. 2022.06.04.
- Generalized Resampled Importance Sampling Foundations of ReSTIR. Daqi Lin, Markus Kettunen, Benedikt Bitterli, Jacopo Pantaleoni, Cem Yuksel, Chris Wyman. ACM ToG. SIGGRAPH. 2022.07.24.
- 일명 GRIS 혹은 ReSTIR PT 논문
- 블로그 정리본
초록
- ReSTIR 논문
- 문제: 수백만 개의 동적인 광원이 있는 환경에서 효율적으로 렌더링하기
- 해결: ReSTIR 알고리듬.
- interactive rate
- 고품질
- 복잡한 자료구조 X
- ReSTIR GI 논문
- 문제: 실시간 어플리케이션에선 픽셀 당 추적할 수 있는 광선의 수가 매우 적음 -> ReSTIR로 일부 해결 -> 하지만 간접광은?
- 해결: ReSTIR GI 알고리듬.
- 매우 병렬적인 GPU 구조에 알맞음
- 다중 튕김 간접광 경로에서 resample
- 오류율 낮음
- RTXDI 논문
- 문제: ReSTIR를 게임에 쓰기엔 좀 비쌈
- 해결: 여러 알고리듬적 해결 방법 제시
- Volumetric ReSTIR 논문
- 문제: 복잡한 여러 조명이 있을 때 실시간으로 volume rendering하기가 어려움
- 해결: ReSTIR 기술 활용함.
- ReSTIR PT 논문
- 문제: Scene은 복잡해지고, 요즘 실시간에서도 ray tracing하려고 적은 sample로도 고품질 내려고 함. 이거 때문에 ReSTIR 기술이 나와서 요즘 설침. 근데 sample 재사용하게 되면 correlation이 발생해서 RIS가 원래 제공하던 수렴 보장성이 사라지게 됨.
- 해결: GRIS 알고리듬.
- sample correlation
- 이론적 토대 완성
- DDGI ReSTIR 논문
- 문제: 조명이나 기하적 특성이 복잡한 scene에서의 실시간 전역 조명. 난반사나 준난반사는 여러 꼼수가 있는데 정반사 쪽이 적은 sample로 어캐 처리하기가 복잡함.
- 해결: ReSTIR + DDGI
공통적인 문제:
- 복잡하고 동적인 scene에서 적은 sample 만으로 실시간성과 퀄리티를 둘 다 잡자!
- ReSTIR는 직접광만
- ReSTIR GI는 간접광까지
- ReSTIR PT로 이론적 토대
- DDGI ReSTIR는 정반사에 집중
도입
- ReSTIR 논문
- 문제
- 몬테 카를로 경로 추적법 다이스키
- 근데 조명이 여러 개일 때 직접광 처리하는 부분이 좀 문제임
- 조명 하나 하나 전부 그림자광 쏘려고?
- 게다가 이걸 실시간에 해야함
- 즉, scene이 정적이지 않으며, 쏠 수 있는 광선의 수가 적음
- 이거 해결하려고 요오즘 것들은 디노이징 기술에 집중함
- 근데 어차피 디노이징이 시간을 안 먹는 것도 아니고, 걔도 짧은 시간에 좋은 품질 내려면 애초에 들어오는게 좋아야 함… sample 적은 애를 주면 디노이저도 PPAP 춰야함…
- 결국 애초에 디노이저에 들어갈 애에서 sample을 잘 해줘야 함
- 해결
- 여러 조명으로부터 오는 단일 튕김 직접광을 sampling해주는 실시간 및 동적 scene 전용 알고리듬!
- Talbot 20051의 “resampled importance sampling”, 일명 RIS 알고리듬에 기반함
- 어떤 한 분포에서 sample 집합을 뽑음.
- 이 집합에서 가중치를 둔 부분집합을 또 고르는 알고리듬.
- 이때 적분할 함수에 가장 잘 알맞는 부분집합을 고르게 됨.
- 여기에 작은 고정된 크기의 자료구조인 “저장소reservoir”를 사용함.
- 이때 sampling 알고리듬2을 활용해 저장소에 sample들을 집어 넣음
- 안정적인 실시간 보장
- 이때 sampling 알고리듬2을 활용해 저장소에 sample들을 집어 넣음
- 픽셀마다 시공간적 이웃의 통계를 재사용하여 sampling PDF의 품질을 높임
- 픽셀의 색이 아니라 sampling 확률을 재사용하는 것임
- 문제
- ReSTIR GI
- 문제
- 경로 추적법이 워낙 유연하고 일반적으로 사용할 수 있다보니, 조명도 복잡하고, material이나 geometry도 복잡한 scene을 보통 갖는 실시간 어플리케이션에선 입맛을 다실 수 밖에 없음
- 근데 이거 연산 비용이 좀 비쌈
- RTX 있어도… 비쌈…
- 잘 쳐줘봤자 실시간에 픽셀당 광선 열 몇 개 정도?
- 디노이저 물론 잘 되긴 하는데, 애초에 처음부터 sampling을 잘 해줘야 함
- 해결
- 경로 추적으로 다중 튕김 전역 조명을 실시간으로 처리하자!
- 직접광에 썻던 ReSTIR 알고리듬 사용하자!
- ReSTIR이랑 다르게 초기 sample을 shade할 지점 위의 방향을 의미하는 local sphere 공간에 초기 sample을 둠
- 여기서 sampling 한 방향으로 광선을 쏴서 도달한 지점이 있을텐데, 이 지점에서 shade할 지점으로 산란하는 빛의 양이 곧 그 sample의 RIS 가중치가 됨.
- 이 지점을 시공간으로 resample하는 것!
- 여기서 reservoir는 그냥 단순 screen-space buffer임
- 문제
- RTXDI 논문
- 문제
- “야, 오프라인 렌더러들아, 너네 이렇게 좋은 걸(몬테 카를로 광선/경로 추적법) 너네만 꿀 빨고 있었냐? 나도 좀 써보자”
- 어라 근데 쓰려고 하니깐 생각보다 좀 연산 비용이 비싸네… RTX는 필수고… 귀족들의 문화인가…
- 디노이징을 하니까 그래도 좀 괜찮네
- 근데 이게 제대로 되면?
- 그림자도 따로 안 해도 돼, AO도 따로 안 해도 돼…
- 아니 그래서 제대로 되시냐고? RTX 3090 없으면 몰?루 아니냐고~
- Scalability가 있어야 하구나!!
- ReSTIR 이놈 보니까 이런 면에서 좀 하자가 있어서 몇 가지 좀 손 봐야함.
- 해결
- Bias의 원인, 그리고 노이즈와의 관계
- RIS의 메모리 일관성 높이기
- 매개변수들 조정하기
- 프레임 당 global barrier 줄이기
- shading과 sample 재사용 디커플링하기
- Visibility 재사용해서 성능 높이는 대신 약간의 퀄리티 포기하기
- 문제
- Volumetric ReSTIR 논문
- 문제
- 요즘 다 participating media 사용함
- 연기, 불, 구름, 등등…
- 근데 이거 실시간으로 하는게 여간 어려운 게 아님
- rasterization도 아예 따로 처리하드만…
- 실시간 경로 추적에서 이걸 지원하면 나머지도 실시간 경로 추적으로, 이거까지 실시간 경로 추적으로? 이거 일관성 있네요
- 요즘 다 participating media 사용함
- 해결
- RIS와 ReSTIR을 좀 더 일반화해주자!
- 이걸 경로 공간으로 일반화해하는 것임
- volumetric 적분식을 효율적으로 추정해주는 식
- 더욱 강력한 temporal 재사용을 위한 temporal reprojection과 실용적인 velocity resampling
- 경로 공간 전달 추정 최적화
- RIS와 ReSTIR을 좀 더 일반화해주자!
- 문제
- ReSTIR PT 논문
- 문제
- 요오즘 렌더링의 핵심은 몬테 카를로 알고리듬임
- RTX 덕에 이제 실시간으로 가능함
- 근데 게임에서는 쓸 수 있는 프레임당 광선 수가 제한되어있음
- 사실상 픽셀 당 경로 하나 수준임
- importance sampling으로 sample 분포를 개선해서 sample이 적을 때의 분산을 줄일 수는 있는데, 복잡한 전역 조명 환경에서는 한계가 있음
- 분포를 구하기가 힘들어? 그럼 sample을 뽑아서 걔네로 분포를 만들어~ (ReSTIR)
- 이상적으로는 충분히 reuse를 하면 각 sample이 “완전한” importance 분포로 수렴할 것임
- 근데 이런 무작위 분포의 수렴을 제대로 연구한 게 얼마 없음.
- 게다가 ReSTIR는 핵심 문제를 무시함: RIS는 독립항등분포에 해당하는 sample을 가정함. 주로 하나의 분포에서 옴. 근데 reuse를 하게 되면 이 가정을 위반하게 됨.
- 경험적으로는 충분히 correlation이 작으면 수렴을 방해하진 않음
- 근데 그래서 correlation을 줄이는게 정말 수렴을 보장하는지는 확실하지 않음
- 해결
- generalized resampled importance sampling (GRIS) 알고리듬
- 독립항등분포 가정도 처리하면서도 복잡한 sampler의 수렴을 이해하고, 설계하고, 논의하는 새로운 이론적 토대임
- 사실상 RIS나 ReSTIR는 GRIS의 한 특수한 케이스인 것임
- 기여한 점:
- shift mapping을 통해 다른 픽셀의 경로로부터 RIS 도출
- 무편향성과 수렴의 조건
- 수렴 제한 조건을 만족하면서 분산을 낮추는 MIS 가중치 도출
- ReSTIR 알고리듬 중 어떤 부분이 수렴을 보장하는데 가장 중요한지에 대한 설명
- 경로를 시공간적으로 재사용할 때 노이즈 제어하는데 도움이 될 제대로된 shift mapping
- BSDF lobe에 특화된 연결로 더 나은 성능과 품질을 보이는 shift mapping 설계
- 경로 재사용하는 ReSTIR PT 알고리듬 도출
- generalized resampled importance sampling (GRIS) 알고리듬
- 문제
- DDGI ReSTIR
- 요즘 실제 제품으로 나오는 물리 기반 렌더러들은 단방향 경로 추적 알고리듬을 메인으로 사용함
- 근데 기하적으로나 조명적으로나 복잡한 scene에서는 경로 추적을 사용하면 분산이 매우 높아짐 (즉, 노이지함)
- 그래서 몬테 카를로 기반으로 분산 줄이는 여러 방법들이 소개됨
- 대표적으론 importance sampling 계열이 있음
- 그럼에도 좋은 품질로 렌더링하려면 픽셀 당 sample 수백 개 필요함
- GPU로 이제 광선 추적 가능하고, 디노이저도 생겼지만, 그럼에도 연산 비용은 간접광 몇 개(보통 하나) 정도 밖에 안 됨
- 그래서 게임에선 importance sampling + 전역 조명 근사하는 방법을 사용해야 함
- 대표적인게 world-space에 irradiance probe를 배치해서 다중 튕김 간접광을 근사하는 것
- 근데 요즘 ReSTIR 덕분에 sampling이 매우 좋아짐
- 보통 게임에서 sampling은 full-screen post-processing(디노이징 등) 직전에 처리함. 그래야 sampling 한 다음에 디노이징을 하니까
배경지식
렌더링 방정식
어떤 점 y에서 직접광에 의해 ω 방향으로 반사되는 radiance L은 광원의 표면 A에 대한 적분식으로 다음과 같이 구할 수 있음:
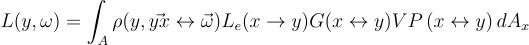
여기서 ρ는 BSDF, Le는 광원이 내뿜는 radiance, V는 x와 y 사이의 상호 가시성, G는 역 제곱 거리와 코사인 항을 갖는 기하적 요소.
Importance Sampling (IS)
이때 위의 식을 x에 대해 간략하게 표현한다면:
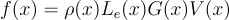
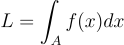
이걸 몬테 카를로 Importance Sampling(IS)를 통해 source 확률밀도함수 p(xi)에서 N 개의 샘플 xi 고르면 적분식을 estimate 할 수 있게 됨:
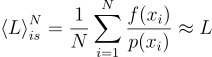
이때 f(x)가 0이 아닐 때 p(x)가 양수이기만 하면 무편향성을 띰. 또한 이상적으로는 p(x)가 f(x)와 상관관계가 있으면 분산이 낮아짐.
다중 Importance Sampling (MIS)
실제로는 f(x)에 비례하여 샘플링하는 건 불가능. 특히나 V(x) 항 때문에 더더욱 문제임. 근데 적분식의 강 항(BSDF, Le 등)에 대하여 샘플링하는 건 ㄱㅊ임.
즉, M 개의 샘플링 방법 ps이 존재할 때, 각 s번째 샘플링 방법마다 Ns 개의 샘플을 뽑고, 이들을 하나로 합쳐서 하나의 가중치가 부여된 estimator로 만들어 줄 수 있음. 이것이 바로 MIS:
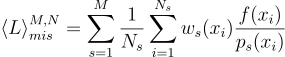
이때 가중치 ws 들의 합이 1만 이루기만 하면 MIS는 무편향성을 가짐. 대표적인 가중치 함수로는 balance heuristic 함수를 쓺:
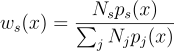
Resampled Importance Sampling (RIS)
MIS가 각 항의 선형 결합으로부터 샘플링을 했다면, RIS는 이 항들의 곱에 근사approximately하게 비례하여 샘플링을 해주는 것임.
근데 애초에 IS를 이유는, 당연히 아래의 식과 같이 완벽한 source PDF를 구할 수 있다면 아무런 문제가 되지 않을 것임:
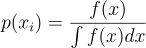
근데 애초에 우리가 몬테 카를로를 하는 이유 자체가 적분을 못해서인데, 여기서 저 적분을 구하라고 하는게 말이 안되잖음.
그래서 몬테 카를로는, “알아서 pdf p 잘 구하시구요, 그걸 이 방법으로 하면 대충 estimation 가능해요~”라는 거고, IS는 “pdf p가 f에 비례하면 좀 더 좋아요~”라는 것이고, MIS는 “f에 비례하는 p 구하기 어려우시죠? 꼼수로 선형 결합을 드리겠습니다~”라는 것이다.
위의 식처럼 p를 구하면 완벽한 IS가 될 것이지만, 그러려면 애초의 적분이 필요하니까…
근데 완벽한 p를 구한다는 발상을 반대로 생각해서, 애초에 완벽한 p를 근사를 해보려고 시도할 수도 있다. 즉, 저 적분을 한 번 근사해보자는 것이다.
즉, 현실적으로 f에 대해서 샘플링하기가 힘드니까, 일단 f를 샘플링의 대상이 아니라, 우리가 구할 target 함수 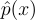 로 다르게 바라보자는 것이다. (이때 이 target 함수는 PDF처럼 normalized 된 상태가 아닐 것이다!)
로 다르게 바라보자는 것이다. (이때 이 target 함수는 PDF처럼 normalized 된 상태가 아닐 것이다!)
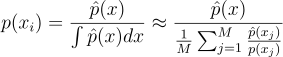
그렇다면 이제 이 target을 근사할 새로운 source PDF p가 생긴다. 즉, 적당히 최적이면서 구하기 쉬운 source 분포 p로부터 한 개 이상(M ≥ 1)의 후보 샘플들(x = {x1, …, xM})을 우선 뽑는 것이다. 이제 여기서 임의의 z 번째 샘플 하나를 다음 이산 확률로 뽑는다:
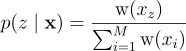
이때 가중치 w는 다음과 같다:
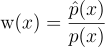
이렇게 되면 자연스럽게 구하려는 식을 다시 쓸 수 있게 된다:
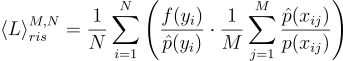
여기서 N 개의 샘플이 아니라, 하나의 샘플만을 다루게 된다면 식을 다음과 같이 정리할 수 있다:
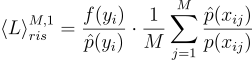
이렇게 되면 마치 y 라는 샘플을 에서 뽑은 것처럼 속여서 사용할 수 있게 된다. 뒤에 있는 괄호 안에 있는 내용은 “아, 이게 보면 분포에서 뽑은 것처럼 보이긴 하는데, 사실은 p에서 온거고, 이걸로 근사를 하려고 했던거에요~”라고 알려주는 거다.
RIS는 M, N ≥ 1이고, f가 0이 아닐 때 p와 가 양수기만 하면 무편향성을 띤다.
RIS 알고리듬:
void ResampledImportanceSampling(float& outSample, float& outWeightSum, size_t numCandidates, const Pixel& pixel)
{
float* samples = reinterpret_cast<float*>(::malloc(numCandidates * sizeof(float)));
float* weights = reinterpret_cast<float*>(::malloc(numCandidates * sizeof(float)));
::memset(samples, 0, numCandidates * sizeof(float));
::memset(weights, 0, numCandidates * sizeof(float));
float weightSum = 0.0f;
for (size_t i = 0; i < numCandidates; ++i)
{
samples[i] = GenerateSample(SourcePdf);
weights[i] = TargetPdf(samples[i]) / SourcePdf(samples[i]);
weightSum += weights[i];
}
// Select from candidates w
// Compute normalized CDF C from weights
// draw random index z ∈ [0, M) using C to sample ∝ w_z
size_t z = GenerateSample(C);
outSample = samples[z];
outWeightSum = weightSum;
}
참고문헌
- Talbot, Justin and Cline, David and Egbert, Parris. Importance Resampling for Global Illumination. Eurographics Symposium on Rendering (2005).
- Efraimidis, Pavlos S. and Spirakis, Paul G. Weighted random sampling with a reservoir. Information Processing Letters, Volume 97, Issue 5, 16 March 2006, Pages 181-185.
Latex
- Rendering Equation
L(y, \omega) = \int_{A}{\rho{ \left ( y, \vec{yx} \leftrightarrow \vec{\omega} \right ) } L_{e}{\left(
x \rightarrow y \right)} G{\left(x \leftrightarrow y \right )}VP\left(x \leftrightarrow y \right )dA_x}
- Importance Sampling
L = \int_{A}{f{\left(x\right)}dx}
f{\left(x \right )} = \rho{\left(x \right )}L_{e}{\left(x \right )}G{\left(x \right )}V{\left(x \right )}
\left \langle L \right \rangle^{N}_{is} = \frac{1}{N}\sum^{N}_{i=1}{\frac{f{\left(x_{i} \right )}}{p{\left(x_{i} \right )}}}\approx L
- MIS
\left \langle L \right \rangle^{M, N}_{mis} = \sum^{M}_{s=1}{\frac{1}{N_{s}}\sum^{N_{s}}_{i=1}{w_{s}{\left(x_i\right)}\frac{f{\left(x_{i} \right )}}{p_{s}{\left(x_{i} \right )}}}}
w_{s}{\left(x\right)} = \frac{N_{s}p_{s}{\left(x \right )}}{\sum_{j}{N_{j}p_{j}{\left(x \right )}}}
- RIS
p{\left(z \mid \textbf{x} \right )} = \frac{\textrm{w}{\left(x_{z} \right )}}{\sum^{M}_{i=1}{\textrm{w}{\left(x_{i} \right )}}}
\textrm{w}{\left(x \right )} = \frac{\hat{p}{\left(x \right )}}{p{\left(x \right )}}
p{\left(x_{i} \right )} = \frac{f{\left(x \right )}}{\int{f{\left(x \right )}dx}}
p{\left(x_{i} \right )} = \frac{\hat{p}{\left(x \right )}}{\int{\hat{p}{\left(x \right )}dx}} \approx
\frac{\hat{p}{\left(x \right )}}{\frac{1}{M}\sum^{M}_{j=1}{\frac{\hat{p}{\left(x_{j} \right )}}{p{\left(x_{j} \right )}}}}
\left \langle L \right \rangle^{M, N}_{ris} = \frac{1}{N}\sum^{N}_{i=1}{\textrm{w}{\left(x_{i}, y_{i}\right)}\frac{f{\left(y_{i} \right )}}{\hat{p}{\left(y_{i} \right )}}}
\textrm{w}{\left(x_{i}, y_{i}\right)} = \frac{1}{M}\sum^{M}_{j=1}{\textrm{w}_{ij}}
\left \langle L \right \rangle^{M, N}_{ris} = \frac{1}{N}\sum^{N}_{i=1}{\left( {\frac{f{\left(y_{i} \right )}}{\hat{p}{\left(y_{i} \right )}}} \cdot {\frac{1}{M}\sum^{M}_{j=1}{\frac{\hat{p}{\left( x_{ij} \right )}}{p{\left(x_{ij} \right )}}}}\right ) }
\left \langle L \right \rangle^{M, 1}_{ris} = {\frac{f{\left(y_{i} \right )}}{\hat{p}{\left(y_{i} \right )}}} \cdot {\frac{1}{M}\sum^{M}_{j=1}{\frac{\hat{p}{\left( x_{ij} \right )}}{p{\left(x_{ij} \right )}}}}
- Weighted Reservoir Sampling
P_{i} = \frac{\textrm{w}{\left(x_{i} \right )}}{\sum^{M}_{j=1}\textrm{w}{\left(x_{j} \right )}}
W{\left(z \right )} = \frac{1}{\hat{p}{\left(z \right )}M}\sum^{M}_{j=1}{\frac{\hat{p}{\left(y_{j} \right )}}{p{\left(y_{i} \right )}}}
\left \langle L \right \rangle^{M, 1}_{ris} = f{\left(y_{i} \right )} W{\left(y_{i} \right )}